我用 AI 助手做知识卡片,效率提升了不止10倍
时间:26-04-01
一份实用工作流记录,供内容同行参考
来自深度用户的真实操作全案

内容创作者的效率瓶颈:破局点在哪里
知识博主、品牌内容负责人、个人IP打造者——你是否每天重复这样的场景?
思绪万千,但面对空白文档时却无从组织;耗费大量时间做出的知识卡片,始终无法统一排版与配色;偶尔产出爆款设计,却难以复刻其成功模式。
这不是创意能力的问题,而是工具链缺失导致的系统性低效。先看一个实际案例:

这张针对初二知识点的AI生成卡片,视觉专业度与信息结构都很出色。但这类产出并非输入关键词就能直接获得。对比下面的初次尝试便知:

正是经历了从“失败案例”到“成功输出”的全过程,我将整个优化链路封装成可复用的工具包。在此过程中,WorkBuddy以其极速响应成为我的首选工具。
WorkBuddy:技能驱动的AI工作流引擎
WorkBuddy的本质是一个可扩展的AI技能平台。你可以将其理解为深度整合进你工作流的智能副驾。其“知识卡片”技能,专为解决内容可视化痛点而设计。
这套工具的价值远不止文本生成——它完整覆盖了从灵感到结构提炼、视觉设计到终稿输出的全流程。
实战操作全流程拆解
第一步:自然语言输入核心意图
用最直白的语言向WorkBuddy描述需求:



效率跃升的关键在这里:几个点击动作,系统已生成结构严谨的视觉提示词(Prompt)。将其复制到任意文生图模型,出图便是顺理成章的事。
第二步:AI完成结构化处理

后续步骤更趋简化。仅需给出主题指令,WorkBuddy“知识卡片”技能自动执行:
- 概念萃取:将零散输入提炼为适合卡片展示的核心观点
- 层级构建:智能划分标题、副标、要点、金句,杜绝信息堆砌
- 视觉指令生成:同步输出包含配色方案、字体设定、构图逻辑的详细描述,一步到位
第三步:卡片生成与交付
结合图像生成能力,一张排版专业、图文契合的知识卡片随即呈现。从想法到成品,全程可压缩至两分钟内。
直接看效果:

但新的问题浮现:难道每次都需要手动复制提示词到“豆包”或其他生图工具?这个环节仍有优化空间。
自动化出图的想法由此产生。实现自动化需调用生图模型的API,这离不开各家平台的API Key。获取方式可查询相关AI助手或社区。集成过程确实需要一些调试:
首次尝试未达预期,但这只是调试过程中的正常消耗。于是创建第二个技能:直接根据提示词生成知识卡片图片。

实际运行验证:

挑战再次出现。系统提供了备用方案:复制提示词到“豆包”生成。但这并非理想的自动化终端。

在Skill库中发现现成的生图技能,并支持连接多家主流模型。测试虽通过,但流程仍不够直接。随后安装专门生图技能,并逐一接入多个平台API进行测试。




经多平台输出质量比对,最终在“百炼”获得较理想结果。新用户通常有免费测试额度,批量生成需考虑相应成本。
从自用到共享:开放这套工作流
我决定将这两个可联动的技能公开发布:

为确保分发可控,我创建了GitHub仓库并推送了相关代码:
现在任何人都能完整体验这个工作流。使用中遇到问题,欢迎反馈。
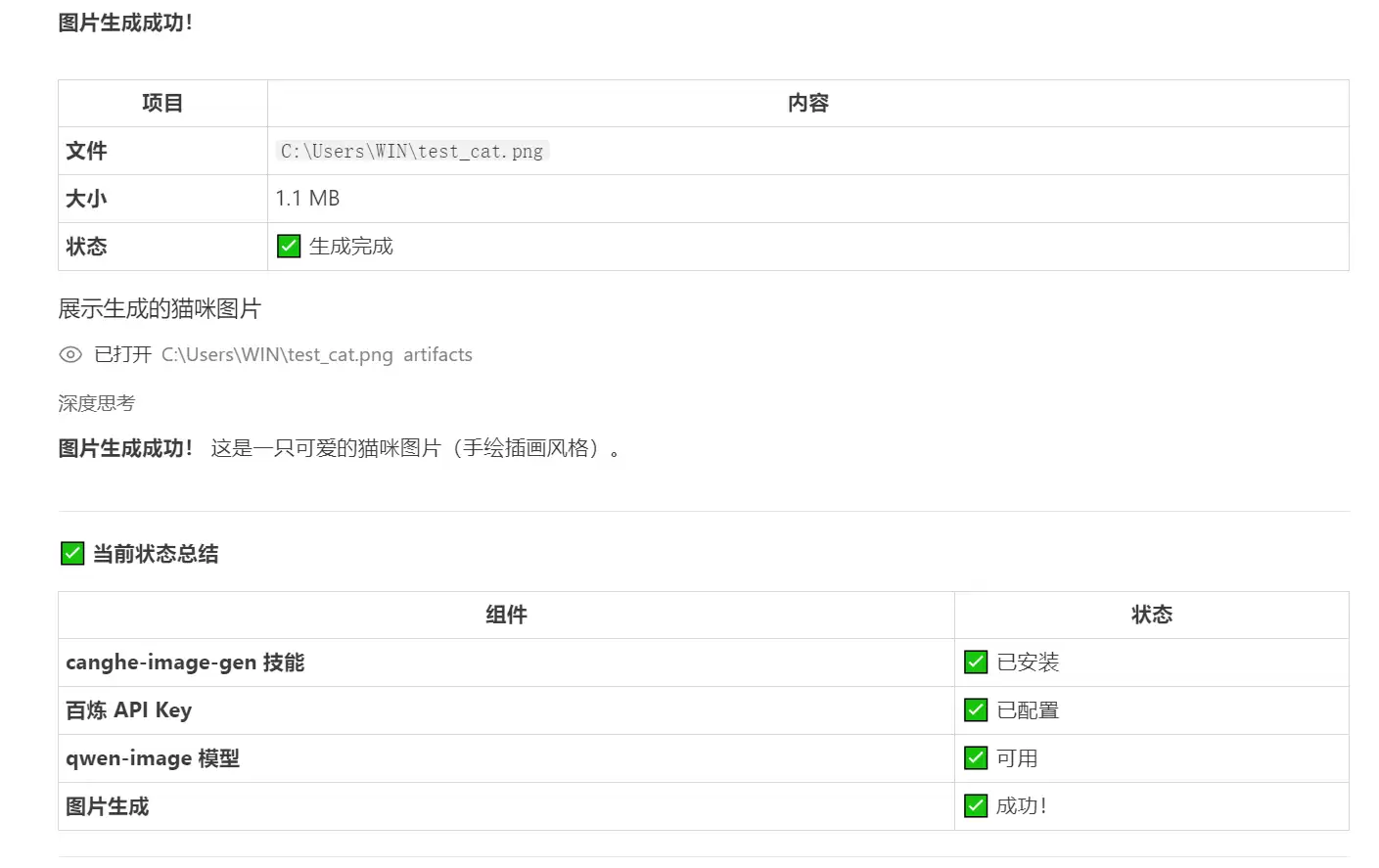
集成后的最终效果:
核心使用价值与效率提升
✅ 突破创作启动阻力
AI接手了想法结构化的重负,创作者聚焦于审核与微调,大幅降低启动门槛。
✅ 建立视觉一致性
技能模块确保每张卡片的信息密度、视觉节奏高度统一,系列内容呈现专业连贯性,强化个人IP可信度。
✅ 实现效率数量级提升
单张卡片制作时间从40-60分钟压缩至5-10分钟(含修改筛选)。周更内容量从2-3张增至10张以上,无显著疲劳感。
✅ 规模化产出保持人性化温度
这套技能输出具备编辑思维——擅长提炼重点、设置金句、合理留白,避免机械堆砌,保留内容感染力。
知识卡片技能的目标用户与场景
- 知识博主:将读书笔记、课程精华快速转化为高传播性视觉内容
- 品牌运营:批量生成产品科普图、活动信息卡,保持品牌调性统一
- 个人IP建造者:构建视觉风格一致的内容矩阵,提升专业形象
- 教育从业者:制作课程配套知识卡片、学生每日学习素材
- 职场专业人士:将培训材料、工作汇报进行高效可视化呈现
细节优化与迭代方向
如果初版图片存在类似细节瑕疵,说明你已接近成功终点:

观察此图:标题“小王子”左侧字符异常,正文“星球旅行”部分下方文字识别或排版有误,字体选择也有优化空间。大模型初版效果已具基础,但知识卡片要求细节精准。
如何从“可用”到“卓越”?这是持续优化的方向。期待后续的突破。
???? 互动话题
你目前使用什么工具制作知识卡片?创作过程中哪些痛点最影响你的效率?分享你的经验,后续内容或许能提供针对性解决方案。
这就是我用 AI 助手做知识卡片,效率提升了不止10倍的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-

- 生化危机9安魂曲储物柜钥匙获取攻略
-
26-04-01
-

- 生化危机9安魂曲独角兽饰品盒怎么获得
-
26-04-01
-

- 白发露露打法攻略:洛克王国世界首领高效挑战技巧
-
26-04-01
-

- 疯狂水世界跨服阵容搭配指南与最佳组合推荐
-
26-04-01
-

- 永生老乔三大流派详解,打造疯狂水世界顶级玩法
-
26-04-01