AI 口语教学新解:即构 AI 数字人双场景发力
时间:26-04-01
角色与核心任务
从口语启蒙到高阶表达,学习者的核心障碍往往不在于词汇或语法,而在于跨越心理门槛,实现从容、自信的即时对话。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
然而,实现流畅口语的路径上布满了现实的阻碍:一对一外教成本高昂,预约困难,师资质量难以保证且难以规模化复制,使得高效的语言习得成为一个昂贵的承诺。
要系统性解决这些瓶颈,融合前沿AI技术的多模态交互方案,正成为最具可行性的战略选择。
通过整合大语言模型的深度理解、实时互动架构、以及RTC、语音识别与数字人技术,AI驱动的口语陪练得以提供低成本、高可及性的沉浸式对话环境。这为教育产品实现规模化、个性化与普惠化交付,提供了坚实的技术基础。
但市场现状却揭示了理想与执行之间的鸿沟。当前主流的口语教学模式,无论是传统范式还是早期AI尝试,均未能全面满足用户的核心需求。
为何传统「真人外教」与「早期AI口语教学」模式均遇瓶颈?
目前的口语教学市场,在产品模式与用户体验上普遍面临增长天花板。
依赖纯真人外教的模式,受限于高昂的边际成本和难以标准化的服务质量。每课时的高昂成本严重侵蚀机构利润,优质师资的稀缺性与排课的不灵活性,更是阻碍了服务的普及与连续性。
而初代AI口语产品,则常因交互体验的断裂而流失用户。许多产品仍停留在异步语音消息或基础语音识别阶段,缺乏实时音视频交互带来的沉浸感。AI无法感知情绪、不支持自然打断,加之数字人形象呆板,导致对话真实性不足,用户参与度和长期留存率自然低迷。
更深层的问题在于需求分化。不同年龄段与水平的用户,其口语练习目标截然不同,这意味着通用的解决方案必然失效。
对于语言启蒙阶段的儿童,关键在于通过趣味互动激发内在兴趣,建立正向的情感联结。而对于具备一定基础的成人或备考学员,他们需要的是高度还原真实场景的实战演练,追求的是实用的沟通技能与即时的反馈纠正。
正是基于对上述分层痛点的精准洞察,ZEGO凭借其底层实时互动与大模型能力,推出了「AI数字人口语教学双场景方案」,分别针对少儿启蒙与成人实战进行深度优化。该方案旨在帮助教育伙伴大幅降低内容开发与运营成本,同时显著提升学生的学习动力与效果,重塑一对一口语教学的价值链。
ZEGO AI数字人口语教学双场景方案
1. AI少儿口语教学
针对少儿英语启蒙的认知与兴趣特点,本方案配备了专为儿童设计的互动体系:
首先支持灵活的形象定制。基于自研的数字人生成引擎,仅需单张照片即可快速生成适用于教学场景的专属数字人教师。支持从真人仿真到3D卡通等多种风格,机构可直接导入自有IP形象,使数字人外观更符合儿童的情感认知。
其次是丰富的拟真行为库。数字人能够基于对话关键词,自然地触发点头、转身及点赞、鼓励等手势动作。这种生动的多模态反馈,能够给予孩子更即时、更具象的互动回应,有效维持其学习专注度与积极性。
最后是关键的多模态情绪感知。方案可对学生端语音进行实时情绪识别,让AI能“感知”孩子的情绪状态。同时,数字人结合带有多情感音色的TTS技术,能够输出鼓励性、兴奋或安抚性的语音反馈,从而构建“敢于尝试-获得认可-持续参与”的积极学习闭环。
2. AI成人口语教学
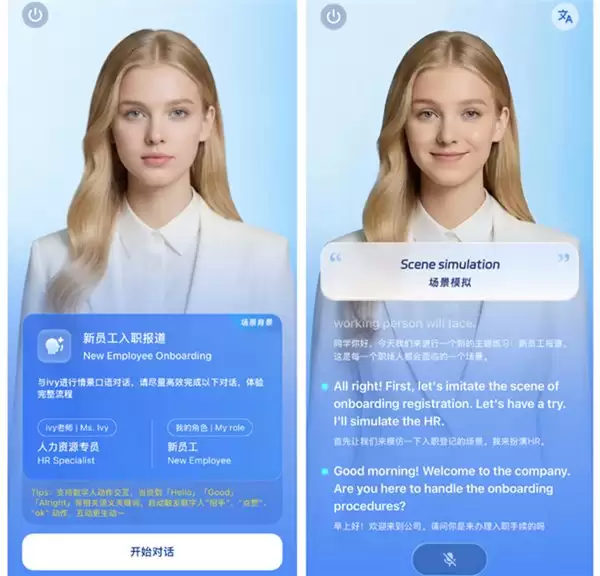
针对成人及高阶学习者的专业需求,方案专注于构建高度拟真的场景化实战环境:
其核心能力在于深度情景还原。教育机构可自主配置各类口语练习场景的剧本与教学目标,例如商务谈判、学术讨论或签证面试模拟,为用户提供高度定制化、即学即用的技能训练。
智能对话推进功能至关重要。依托大语言模型的强上下文理解,AI能在用户表达犹豫时,自然地提供关键词提示或问题引导,确保对话流畅进行,避免练习中断。
此外,发音的准确性与表情的自然度是沉浸体验的关键。方案支持切换多种地道口语口音。更重要的是,ZEGO的核心算法保障了数字人的口型与语音高度同步(驱动延迟低于200毫秒),微表情细腻自然,从而交付了无限逼近真人母语者的对话质感。
ZEGO构建硬核技术底座
能够高效支撑“AI外教”这一复杂交互场景,得益于即构底层坚实的技术架构:
第一,端到端超低延迟通信。通过全球分布式节点实现用户就近接入,并结合端到端的流式处理管线,将AI数字人互动对话的全链路延迟控制在1.5秒内,达到了与真人视频通话相媲美的实时流畅度。
第二,500毫秒内实现自然语音优雅打断。当学生在AI发言过程中插入提问时,系统能精准检测用户语音起始点,在500毫秒内实现平滑打断与快速响应。这从根本上解决了对话轮转不自然的痛点,实现了真正双向、类人的交流节奏。
第三,极具竞争力的成本结构与万级并发支持。ZEGO方案采用灵活的插件化架构,可无缝对接各类主流大语言模型与语音合成服务。这使得单分钟互动成本可优化至0.3元量级。同时,方案支持万级别用户高并发,意味着单一AI教师可同时服务海量学员,轻松覆盖预习、练习、复习等全学习周期的碎片化需求。
这就是AI 口语教学新解:即构 AI 数字人双场景发力的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- 如何关闭高德地图导航语音-高德地图导航语音关闭方法
- 如何查询我的常德无犯罪记录证明-我的常德无犯罪记录证明查询方法
- 咔皮记账怎么同步多设备-咔皮记账如何在多设备间同步
- 知犀思维导图app如何更改颜色-知犀思维导图app怎样变换颜色
- 贾跃亭宣布法拉第未来月底将超额完成机器人首月 20 台交付目标
- 消息称魅族 AR 眼镜品牌 StarV 的 AR 系统团队整体入职雷鸟创新
- realme 全面接入 OPPO 售后服务网络:即日开启过渡整合,4 月起统一提供支持
- openClaw常用操作命令
- openclaw[龙虾]禁用版本升级提示
- 古尔曼:苹果 CEO 候选人 John Ternus 广受高层欢迎,曾扭转产品质量下滑局面








大家还在看
-

- 《神火大陆》希尔神域第11层奇遇任务1攻略
-
26-04-01
-

- 金铲铲之战S17拉亚斯特技能费用介绍
-
26-04-01
-

- 金铲铲之战阿狸的光坏神器效果一览
-
26-04-01
-

- 《蓝色星原:旅谣》芃芃介绍
-
26-04-01
-

- 《无径之林》建筑雕像解锁条件介绍
-
26-04-01