Claude 对 C++/Rust 等底层语言的支持情况
时间:26-04-21
Claude在C++/Rust代码生成中存在内存模型、所有权系统及构建生态理解局限

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
如果你发现Claude生成的C++或Rust代码,在编译时频频报错,或者运行时行为与预期不符,别急着怀疑自己——这很可能不是你的问题。当前阶段,模型对底层语言的内存模型、所有权系统以及构建生态的理解,确实存在一些边界。下面就来具体拆解这些局限,并给出切实可行的应对策略。
一、C++ 支持现状与实操限制
平心而论,Claude处理C++的日常语法、STL容器使用、基础的类设计乃至一些模板模式,已经相当顺手。但一旦触及更底层的领域,比如ABI兼容性、链接时优化(LTO),或者特定编译器的扩展语法(像GCC的__attribute__或MSVC的intrinsics),模型的“知识库”就显得有些力不从心了。它通常会默认采用C++17标准,如果你的项目强制要求C++20的概念(Concepts)或者C++23的范围库(Ranges)等新特性,不事先声明清楚,结果很可能跑偏。
那么,具体该怎么操作呢?
1、标准先行,明确版本。 在提示词里就把标准版本锁死。比如,直接要求:“请生成符合 C++20 标准的 constexpr vector 实现,不依赖第三方库”。把前提条件摆明,能有效缩小模型的“想象空间”。
2、关键注释,引导焦点。 对于涉及资源生命周期的核心代码,比如RAII、移动语义或虚函数表布局,手动加上关键注释来引导模型。例如,在关键位置注明:“此处需确保析构函数不抛异常,且 move 构造函数正确转移资源指针”。这就像给模型画了个重点,让它知道该在哪里集中注意力。
立即学习“C++免费学习笔记(深入)”;
3、静态检查,必不可少。 模型生成的代码,绝不能直接拿来就用。务必用clang++ -std=c++20 -Wall -Wextra(或你项目对应的编译选项)做一遍严格的静态检查。尤其要关注-Wpessimizing-move(悲观移动)和-Wreorder(成员初始化顺序)这类警告,它们往往是潜在问题的信号灯。
二、Rust 支持中的所有权与借用检查适配
转到Rust这边,情况有些类似又有所不同。Claude生成符合Rust语法的代码基本没问题,但Rust的灵魂——所有权系统和借用检查器——才是真正的挑战所在。当代码中间出现复杂的生命周期标注(比如'a: 'b这种嵌套关系)、高阶Trait对象组合(dyn Trait + Send + 'static),或者宏内部的借用规则时,模型很容易产生“幻觉”,给出看起来合理但编译器绝不接受的代码。此外,它对Cargo工作区依赖解析、feature gate的启用逻辑,以及no_std环境的特殊约束,响应也往往不够精准。
应对策略需要更细致:
1、绑定环境,锁定依赖。 在请求中就把crate版本和需要的features钉死。例如:“基于 tokio 1.36 + serde_json 1.0,生成一个异步读取 JSON 并返回 Result 的函数”。这样一来,模型生成的代码才能无缝融入你现有的依赖生态。
2、安全契约,前置声明。 凡是涉及unsafe块的场景,责任边界必须清晰。在提示词里就声明好安全契约,比如:“此函数将调用 libc::malloc,需保证后续由 caller 调用 libc::free,且输入 size 参数不为零”。把约束条件讲明白,能大幅降低生成代码的潜在风险。
3、即时校验,借用检查。 生成代码后,第一时间用cargo check --lib(或对应目标)跑一遍。要特别警惕E0597(悬挂引用)和E0382(使用已移动的值)这类错误,它们是所有权系统问题的典型代表。
三、跨语言互操作场景下的协同校验
当项目进入C++/Rust混合开发的深水区,比如用Rust调用C++动态库,或者反过来,情况就更加复杂了。Claude目前还无法自动推导FFI(外部函数接口)边界的那些“潜规则”:数据对齐方式、调用约定(是__cdecl还是stdcall)、异常能否跨边界传播等等。这些底层协议一旦出错,就是隐蔽的运行时冲击波。
这时候,人工的介入和约束就成了关键的安全绳:
1、C端封装,约法三章。 让模型为C++头文件生成C兼容封装时,必须把规矩立清楚:“所有 extern \"C\" 函数的参数与返回值必须为POD(平凡旧数据)类型,禁止直接传递 std::string 或 std::vector。” 从源头杜绝ABI不兼容问题。
2、Rust绑定,格式锁死。 为Rust编写extern \"C\"绑定时,强制指定格式:#[no_mangle] pub extern \"C\" fn。如果涉及一些非标准的类型映射,可以附加前提说明,比如允许使用#[allow(improper_ctypes)]属性,但必须解释原因。
3、IR比对,终极验证。 一个可靠的终极大招是:使用bindgen或cbindgen工具生成权威的绑定头文件后,分别用编译器输出LLVM中间代码(IR)。然后仔细比对模型生成的函数签名,与IR中实际的@function名称、参数类型、返回类型是否完全一致。这是确保ABI匹配的“金标准”。
四、构建系统与工具链对齐策略
最后,别忘了构建系统这个环节。Claude本身不执行构建命令,它对你本地的工具链版本(比如用的是rustc 1.76.0-nightly还是clang++-16)一无所知。因此,它生成的CMakeLists.txt或Cargo.toml片段,可能会包含过时的语法,或者未经检验的目标平台(target triple)配置。
要让生成的构建脚本更靠谱,可以这么做:
1、提供上下文,描述环境。 在提问前,先把当前的工作环境作为前缀信息提供给模型。例如:“当前系统为 Ubuntu 22.04,rustc 版本 1.76.0,目标平台 aarch64-unknown-linux-gnu”。有了这些信息,模型的输出会更有针对性。
2、CMake脚本,核心为要。 对于CMake,可以要求模型只生成核心的构建指令,如add_library()和target_link_libraries()。对于依赖查找,建议禁用容易出错的find_package()自动探测,改用显式路径指定,例如:find_library(MYLIB REQUIRED PATHS /opt/mylib/lib)。
3、Cargo依赖,精确到点。 对于Cargo.toml,明确要求禁用workspace继承等模糊字段。所有依赖项都必须带有精确的版本号,以及明确的功能(features)列表。例如:tokio = { version = \"1.36\", features = [\"full\"] }。避免使用模糊的版本范围,能从根源上减少依赖冲突。
这就是Claude 对 C++/Rust 等底层语言的支持情况的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- 芯片大神突然离职!帮高通干翻苹果后,他要组建最强铁三角做AI芯片?
- 《碧蓝幻想 Relink 无尽黄昏》 Beta 公开测试
- 燕云十六声如何自动刷原木材料-燕云十六声怎样实现自动刷原木材料
- Meta公司VR/MR眼镜即将调价 4月19日起上涨20%左右
- 外星人嘉年华现场直击:Area-51系列配置拉满,三十周年要发力中国市场?
- 《归零巡礼:亡谍镇魂曲》中文试玩Demo宣传视频
- 网友晒科萨尔K70键盘十年未清洁前后对比,震撼全网
- 京东携手深蓝汽车推出“国民好车” 深蓝L06增程版开启预订新体验
- GEO 哪个最好?2026 年更值得优先关注的 5 家 GEO 服务商分析:头部、靠谱、口碑与性价比怎么看
- 别被10倍光追性能忽悠了!PS6实际帧率提升约3倍








大家还在看
-
- 《17k小说》投稿写小说教程
-
26-04-27
-

- 三角洲行动长弓溪谷3月5日密码攻略2026
-
26-04-27
-
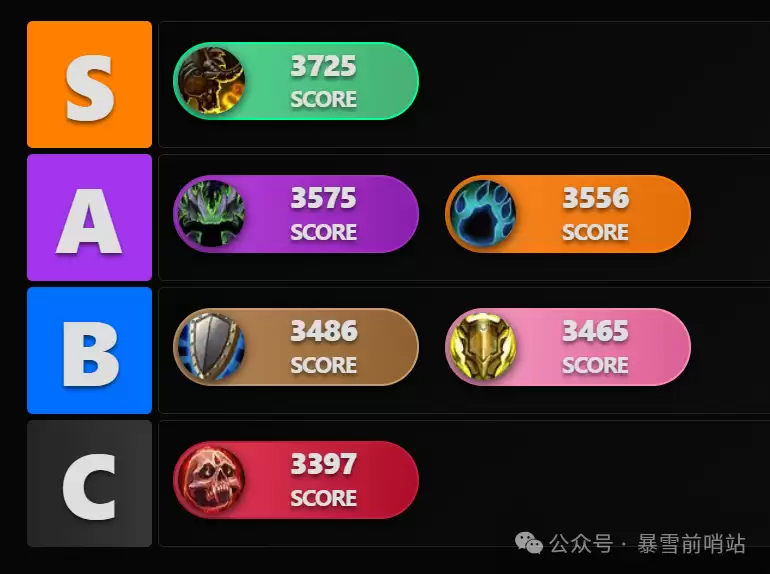
- 魔兽世界12.0坦克职业排名
-
26-04-27
-

- 三角洲行动航天基地3月5日密码攻略2026
-
26-04-27
-

- 我的世界工作方块有哪些2026
-
26-04-27