阿里发布 Wan2.7-Video 视频生成模型:“能导擅演”,聚焦创作全链路
时间:26-04-21
阿里发布 Wan2.7-Video 视频生成模型:“能导擅演”,聚焦创作全链路
今天下午,AI视频创作领域迎来一个重要更新:阿里正式上线了其视频生成模型Wan2.7-Video。这款新模型主打一个“全”字,支持文本、图像、视频、音频全模态输入,并将目光聚焦在“创作”的每一个环节上。从生成到编辑,从复刻到重塑,乃至驱动、续写和参考,整个流程都被覆盖,目标是让视频创作变得更可控、更全能,真正做到“能导擅演”。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
那么,具体怎么个“全能”法?首先,它的控制维度非常丰富。无论是在画面构图、剧情走向,还是局部细节、时序变化上,创作者都能根据自己的想法来指挥调整。这相当于把视频变成了一个可灵活编辑的“文档”,让天马行空的创意有了一一落地的路径。
在编辑能力上,Wan2.7-Video显得相当细腻。比如,你可以通过指令对视频画面的某个局部进行修改,而编辑区域的光影和材质能与原视频无缝融合,看不出修补痕迹。它支持指令式的增删元素——好比说“删掉视频中的火车”;也能替换物体,例如“把胶片替换成盘子”;甚至能修改物体的属性,像是调整建筑的颜色。如果觉得描述不够精准,你还可以直接上传参考图,让模型按图索骥地添加内容。
更妙的是风格与环境的变化能力。你可以让视频里的人物动作保持不变,但背景季节从夏日一键切换到深秋,或者整体画风瞬间变成可爱的羊毛毡风格。这种操作,简直如同打开了平行宇宙的穿梭门。
除了这些创意向的编辑,模型也兼顾了实用性。视频质量提升(比如给黑白老片上色)、视觉理解任务(如主体分割),乃至拍摄方式调整(修改对焦等),多样化的编辑需求都能得到满足。
对于已有的视频素材,二次创作的潜力被大幅释放。你可以在不改变角色身份和核心场景的前提下,对角色的行为、台词,甚至拍摄视角进行碘伏性修改。例如,直接修改角色所说的台词内容,模型会保持其原有的情绪、口型与新台词匹配,并且音色前后统一。或者,仅仅改变行为逻辑:“其他保持不变,让坐在沙发上的女生站起来打游戏”。
同场景下的角色也能彻底“换人”。比如,把打游戏的玩家替换成一位中世纪骑士,手中的控制器换成冷兵器,但握持的姿势却保持不变。拍摄的“语法”也能被重写:机位、视角、景别、镜头类型、焦距等参数都可以调整。一句“将镜头修改为从地面逐渐向升起到俯瞰”,就能让同一段素材呈现出截然不同的电影感。
在视频的生成与控制方面,模型提供了多种“锚点”。通过设定首尾帧、进行视频续写,或者“续写+尾帧”组合的方式,创作者能对剧情走向、画面构图和光影进行精准控制,在保证动态流畅延续的同时,紧紧握住结构的缰绳。
最后,多模态参考能力让创作更具一致性。模型支持图像、视频、音频等多种形式的参考,用以锁定特定外观和音色。值得关注的是,它支持多达5个视频主体参考,确保每个角色都拥有专属音色,并且在多个镜头切换间,角色特征能保持高度一致,这对于叙事连贯性至关重要。
目前,想要体验这一强大工具,可以通过以下两个官方渠道:
阿里云百炼:https://bailian.console.aliyun.com/cn-beijing?tab=model#/model-market/all?providers=wan
万相官网:https://tongyi.aliyun.com/wan
这就是阿里发布 Wan2.7-Video 视频生成模型:“能导擅演”,聚焦创作全链路的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- 芯片大神突然离职!帮高通干翻苹果后,他要组建最强铁三角做AI芯片?
- 《碧蓝幻想 Relink 无尽黄昏》 Beta 公开测试
- 燕云十六声如何自动刷原木材料-燕云十六声怎样实现自动刷原木材料
- Meta公司VR/MR眼镜即将调价 4月19日起上涨20%左右
- 外星人嘉年华现场直击:Area-51系列配置拉满,三十周年要发力中国市场?
- 《归零巡礼:亡谍镇魂曲》中文试玩Demo宣传视频
- 网友晒科萨尔K70键盘十年未清洁前后对比,震撼全网
- 京东携手深蓝汽车推出“国民好车” 深蓝L06增程版开启预订新体验
- GEO 哪个最好?2026 年更值得优先关注的 5 家 GEO 服务商分析:头部、靠谱、口碑与性价比怎么看
- 别被10倍光追性能忽悠了!PS6实际帧率提升约3倍








大家还在看
-
- 《17k小说》投稿写小说教程
-
26-04-27
-

- 三角洲行动长弓溪谷3月5日密码攻略2026
-
26-04-27
-
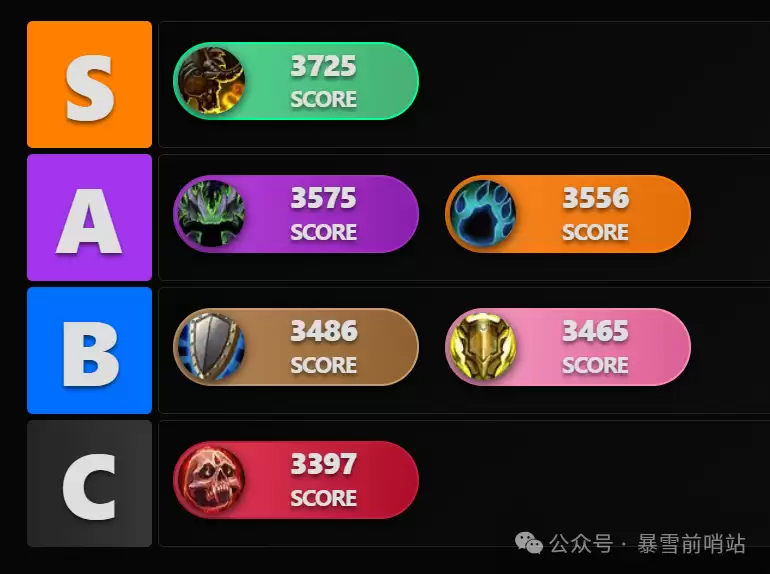
- 魔兽世界12.0坦克职业排名
-
26-04-27
-

- 三角洲行动航天基地3月5日密码攻略2026
-
26-04-27
-

- 我的世界工作方块有哪些2026
-
26-04-27