商汤绝影发布端侧多模态智能体基座大模型Sage ,PinchBench 实测 94% 最佳任务完成率领跑主流大模型
时间:26-04-22
2026 年 4 月 22 日:端侧智能体的新纪元,由商汤绝影开启
就在今天,商汤绝影正式发布了其端侧多模态智能体基座大模型——Sage。这款模型采用了高效的MoE架构,总参数量达到320亿,但激活参数仅为30亿。它的意义何在?简单说,这是行业内首款能在车端实现复杂智能体能力的基座大模型。更令人瞩目的是,在权威的PinchBench评测中,其性能甚至领跑全球一线的云端大模型。目前,Sage已在英伟达Orin X端侧平台上成功部署,标志着技术从云端到车端的实质性跨越。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
当前,AI已全面进入智能体时代。然而,汽车的复杂智能体能力长期依赖云端,端侧模型则受限于算力和参数规模,往往只能完成简单的指令响应。这导致智能座舱陷入一个两难境地:依赖云端,就要忍受延迟和高昂的Token成本;坚守端侧,却又缺失了真正的智能体能力。Sage的发布,恰恰打破了这一僵局,首次将云端级别的智能体能力,实实在在地落地到了端侧。
作为端侧智能体的基座,Sage可以无缝接入OpenClaw、Hermes等主流Agent框架,为更多端侧智能体的落地提供了核心支撑,其应用潜力足以覆盖出行、家庭等全场景。
实力印证:PinchBench上的领跑者
口说无凭,实力需要验证。Sage的能力,已经在国际公开评测中得到了有力印证。在公开的Agent评测基准PinchBench中,Sage端侧大模型的最佳任务完成率达到了惊人的94%。这个数字意味着什么?它超越了包括Claude-Opus-4.6(93.3%)、Claude-Sonnet-4.6(88.0%)、GPT-5.4(90.5%)、Google-Gemini-3(87.0%)、Google-Gemma-4(83.9%)、Qwen3.5-27B(90.0%)、MiniMax-M2.7(89.8%)、MiMo-v2-Pro(87.4%)在内的众多国际主流云侧和端侧大模型。
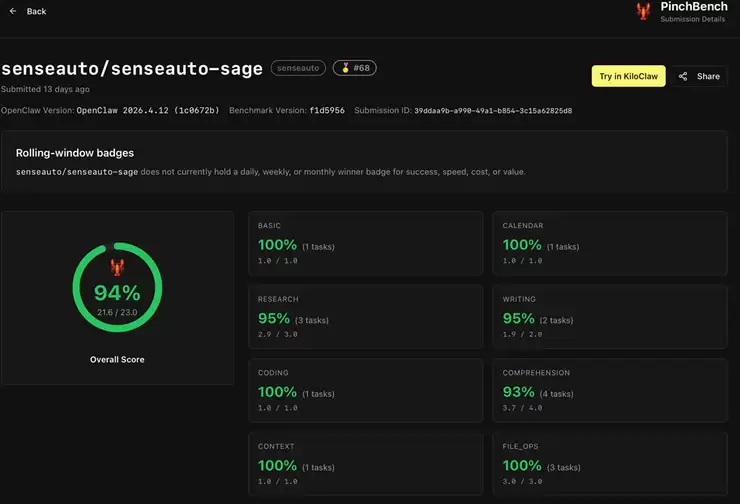
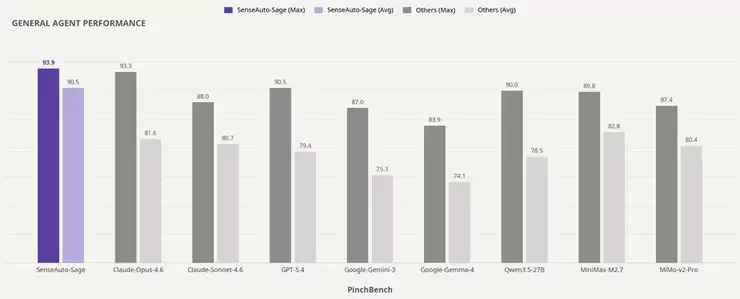
这里有一个关键点值得玩味:Sage仅以30亿激活参数的小体量,就超越了众多参数庞大的云侧旗舰模型。这无疑打破了“只有大模型才能做好智能体任务”的惯性认知,彰显了端侧原生技术路线的高效优势。举个例子,小米MiMo-v2-Pro的激活参数高达420亿,总参数规模超过1万亿。相比之下,Sage的激活参数仅为30亿,所需激活算力仅为前者的1/14;若按模型权重规模近似估算,显存占用更是只有其1/31。然而,在PinchBench上的最佳任务完成率,Sage反而高出6.6个百分点。效率与性能的平衡,由此可见一斑。
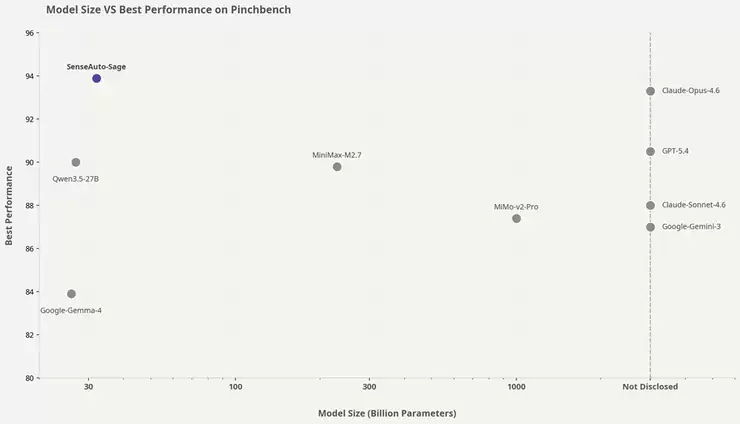
或许你会问,PinchBench究竟有何特别之处?这个由“龙虾之父”Peter Steinberger推荐的公开Agent评测基准,其核心在于面向真实的工作流。它不依赖静态题库,而是随着公开任务库的扩充和版本迭代不断演进。其任务库覆盖写作、研究、编码、分析、邮件处理、文件处理、日程管理、记忆与技能调用等典型场景,重点考察模型在工具调用、多步推理和任务闭环执行中的综合能力。
与此同时,PinchBench要求模型完成真实的任务执行,并综合衡量成功率、速度与成本。因此,其测试周期更长、资源消耗也更高,单任务的token消耗可达数十万量级。也正因如此,模型在PinchBench上取得的精度表现,更能真实反映其在复杂现实场景中的综合能力与稳定性。
据悉,在北京车展期间,商汤绝影将正式推出搭载Sage端侧多模态智能体基座大模型的Sage Box,这无疑是为汽车迈入超级智能体时代,筑牢了核心根基。
凭借两大黑科技,Sage 让座舱从“听懂指令”到“说到做到”
Sage能在PinchBench上跑赢一众国际对手,背后的功臣是商汤绝影在模型后训练阶段自研的两项关键技术:SCOUT和ERL。
以SCOUT和ERL为核心的后训练技术体系,堪称“黄金搭档”:一项让模型“学得又快又省”,另一项让模型“做事不出错”。它们重点突破了智能体在学习效率、训练成本和复杂任务稳定执行上的行业挑战,解决了让车载大模型从“能听懂指令”进化到“能独立办成一件复杂的事”这一公认难题。
SCOUT:让大模型学复杂任务,省 60% 算力
SCOUT(分级协同学习框架)技术,主要解决大模型学习复杂出行场景任务时成本高、试错慢的痛点。在复杂任务能力注入过程中,它可节省约60%的GPU小时消耗。
道理很简单:很多任务涉及空间规划、设备联动、多步决策,如果直接让大模型自己试错学习,过程既缓慢又极其消耗算力。SCOUT的思路很巧妙,叫做“探路与吸收解耦”——先派遣一个轻量级的小模型在任务环境中快速探索一遍,把那些走得通的路径筛选出来,然后再将这些高价值的“经验包”喂给大模型学习。这就形成了“小模型先探路,大模型再吸收”的高效学习机制,在显著降低训练成本的同时,也能让大模型更快地掌握更多真实用车场景技能。
(上述技术成果论文已上传arXiv:https://arxiv.org/abs/2601.21754)
ERL:让模型自己擦掉错误步骤,任务成功率提升 20%
另一项已被机器学习顶级会议ICLR 2026收录的技术,是ERL(可擦除强化学习)。它聚焦于复杂任务链路中的错误识别与纠偏。用户在真实场景中提出的需求,往往需要模型进行多步骤的推理和执行,中间任何一步出现偏差,都可能导致整个任务失败。
ERL的妙处在于,它让模型能够自动识别推理过程中的错误步骤,并对错误内容进行“擦除”并重新生成,从而从源头阻断偏差的扩散。这就像是给模型装上了“边思考边纠错”的能力。这项技术让Sage在多跳复杂推理基准上较此前的最佳水平取得了显著提升。装车实测数据显示,Sage在复杂任务上的完成率提升了20%。
(上述技术成果论文已上传arXiv:https://arxiv.org/abs/2510.00861)
SCOUT和ERL两项技术前后协同,共同推动Sage从语言大模型演进为能够独立完成复杂任务的智能体。再叠加一体化多模态架构与原生训练数据的优势,Sage在能力、成本与量产可行性之间找到了绝佳的平衡点,为打造真正的智能体中枢提供了核心的AI支撑。
端侧跑出全球领先能力,Sage 定义智能上限
如果说PinchBench上94%的任务完成率证明了Sage“能办成复杂的事”,那么,真正决定座舱体验好坏的,是模型在各个专业维度上是否都“够用、够稳、够聪明”。在多项不同能力维度的公开基准测试中,Sage全面领先于本月最新发布的同量级端侧旗舰模型Google-Gemma4,将端侧模型的能力天花板提升到了一个新的高度。
具体来看:在MMLU Pro(跨学科专业知识)测试中,Sage获得76分,领先同级端侧模型约10%,这证明了端侧模型同样具备云端级别的通用知识密度;在GPQA Diamond(研究生级专业推理)测试中,Sage获得77分,提升幅度达33%,凸显了其在复杂推理上的深度;在Human Semantic Understanding(座舱语义与视觉理解)测试中,Sage获得91分,提升32%,这得益于其原生数据建立的独特优势。
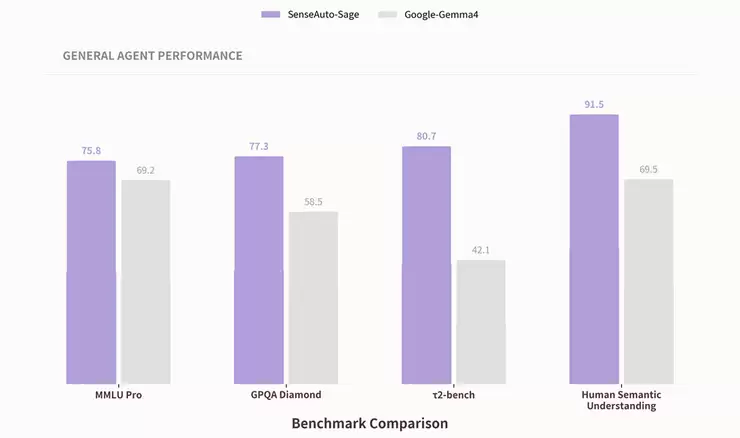
尤其在重点考察任务执行能力的τ2-bench(工具调用与任务闭环)基准上,Sage以80分的成绩,相较Gemma 4实现了38%的提升,接近翻倍领先。这项基准专门评估模型调用工具、走完多步任务的实战能力,可以说是区分“会聊天的模型”与“会办事的智能体”的关键分水岭。τ2-bench上近一倍的领先优势,直接印证了Sage作为端侧智能体基座,在真实任务执行环节上的绝对实力。
从专业基准到场景体验:Sage 真正“懂场景、会思考、能服务”
这些冷冰冰的基准分数,最终要转化为真实的用户体验。落到真实车舱场景中,Sage的表现如何?数据显示,其场景推理精度超过90%,长链路工具调用、逻辑规划、环境感知任务成功率分别达到92%、89%、94%,复杂指令遵循率提升了40%。
在Orin X平台部署下,Sage可实现首字响应时间约0.5秒、单Token推理延迟低至0.03秒、生成吞吐达到80 tk/S,平均任务时长优于主流API模型。这些指标为座舱智能体提供了稳定、实时、可持续在线的运行能力。
这意味着什么?意味着模型可以一次性解析用户“打开空调、播放音乐、导航到公司,顺便提醒我下午三点开会”这样的复合指令,并自动联动空调、影音、导航等车载系统,一气呵成地完成任务闭环。结合传感器对乘员状态与路况的感知,它还能主动提供儿童模式、智能路线调整等贴心服务。
至此,Sage已经不再是那个“被动唤醒、单次响应”的语音助手,而是一个真正懂场景、会思考、能服务的出行伙伴。
总而言之,商汤绝影Sage端侧多模态智能体基座大模型,为舱驾一体方案打通了一条量产可行的模型路径,打破了技术与落地之间的最后壁垒,正在推动智能座舱从基础交互,向高阶的舱驾融合智能体服务时代跨越。
这就是商汤绝影发布端侧多模态智能体基座大模型Sage ,PinchBench 实测 94% 最佳任务完成率领跑主流大模型的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-

- 据报道,大秘境额外拾取(Bonus Rolls)存在重复掉落问题
-
26-04-26
-
- 《异种航员2》游戏中期技巧分享-第3至4个月生存与进展指南
-
26-04-26
-

- Midnight Patch 12.0.5 全职业最佳虚空锻造额外投掷装备指南
-
26-04-26
-

- 《三国:百将牌》不删档版本常见问题FAQ
-
26-04-26
-

- 王者荣耀世界回血方法大全王者荣耀世界角色快速恢复生命值技巧
-
26-04-26