DeepSeek-V4-Flash开源适配摩尔线程S50
时间:26-04-24
DeepSeek-V4预览版发布,国产GPU完成首日极速适配
2026年4月24日,AI领域迎来一个重要节点:DeepSeek正式发布了其V4预览版模型,并同步宣布开源。此次发布最引人注目的特性之一,是其具备百万级字符的超长上下文处理能力,这无疑为处理长文档、复杂对话和多轮推理任务打开了新的想象空间。

几乎在同一时间,另一则消息迅速吸引了业界目光。摩尔线程联合智源众智及FlagOS社区宣布,已在旗舰级AI训推一体GPU——MTT S5000上,完成了对DeepSeek-V4-Flash大模型的“首日极速适配”。这意味着,从模型发布到在国产硬件平台上实现全面优化与部署,整个过程堪称无缝衔接。此次适配不仅完成了部署,更实现了对模型全量核心算子的深度优化。
模型新特性与硬件新要求
为什么这次适配如此迅速且备受关注?关键在于DeepSeek-V4-Flash本身的技术特点。该模型采用了目前前沿的混合专家(MoE)架构,总参数量高达2840亿,而每次推理激活的参数约为130亿。这种设计在保证强大能力的同时,也追求更高的推理效率。更重要的是,它首次引入了FP4与FP8混合精度计算方案。这个技术选择,直接对底层算力硬件提出了更严苛的标准——并非所有GPU都能原生高效地支持这种新型精度格式。
国产GPU的“原生优势”
那么,摩尔线程的MTT S5000为何能担此重任?答案在于其前瞻性的硬件设计。MTT S5000是国内首款原生支持FP8计算的全功能GPU,其内部集成了硬件级的FP8 Tensor Core。这种原生支持带来了什么好处?简单对比一下:相较于传统的BF16或FP16精度计算,FP8设计能够将显存带宽压力直接降低50%,与此同时,计算吞吐量还能实现翻倍提升。这就好比修建了一条更窄但通行效率却翻倍的高速公路,对于追求极致效率的大模型推理场景而言,无疑是巨大的优势。
适配背后的关键技术突破
当然,硬件有优势,还需要软件的深度适配才能释放全部潜能。本次极速适配由智源FlagOS团队主导,其FP8量化工作主要聚焦于两大核心技术方向:FP8核心算子与稀疏注意力(Sparse Attention)算子。
具体是如何实现的?一方面,团队依托FlagTree编译器,实现了精细化的张量形状对齐与矩阵运算加速;另一方面,通过FlagOS-Tune工具自动搜索最优内核配置,其性能表现显著优于传统的人工调优方式。实测数据最能说明问题:启用自动调优后,模型的首词生成时延(TTFT)下降了16.5%,逐词生成时延(ITL)降幅更是达到39.7%,整体吞吐量提升了65.7%。这些数字背后,是推理速度与效率的实质性飞跃。
未来展望与即刻体验
目前,DeepSeek-V4-Flash版本已经在MTT S5000平台上完成了全面适配。而更大规模的DeepSeek-V4-Pro版本(参数量达1.6万亿)的迁移与适配工作,也正在加速推进中。这预示着国产算力与大模型生态的融合正在步入更深、更广的阶段。
对于广大开发者而言,好消息是无需等待。现在就可以通过魔塔平台及HuggingFace获取预置镜像,即刻体验和部署这一强强联合的成果。从模型开源到硬件适配,再到开发者可便捷获取,一个高效、自主的AI算力应用闭环正在快速形成。
这就是DeepSeek-V4-Flash开源适配摩尔线程S50的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-

- 和平精英火箭少女101全出能卖多少钱
-
26-04-26
-

- 杀戮尖塔2各遗物强度高低的排名清单
-
26-04-26
-
- 王者荣耀世界智能构造攻略王者荣耀世界智能通关详细步骤解析
-
26-04-26
-

- 史上最强炼气期境界如何划分等级
-
26-04-26
-
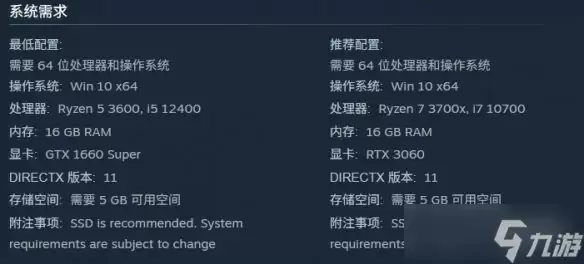
- 《终落之城》配置要求
-
26-04-26