Fluss 0.9 正式发布, 核心亮点都在这里了
时间:26-04-24
Apache Fluss 0.9 发布:流式存储的里程碑,为实时分析与AI注入新动能
Apache Fluss项目刚刚迎来了它的0.9版本,这无疑是项目发展史上的一个重要里程碑。作为一款面向实时分析、AI及重状态流处理的流式存储系统,Fluss 0.9在数据模型、存储处理、生产运维和生态集成等多个维度都实现了显著增强。可以说,它为构建统一、高效的流处理与湖仓一体架构,打下了更坚实的基础。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

那么,这次更新究竟带来了哪些值得关注的亮点?我们不妨深入看看。
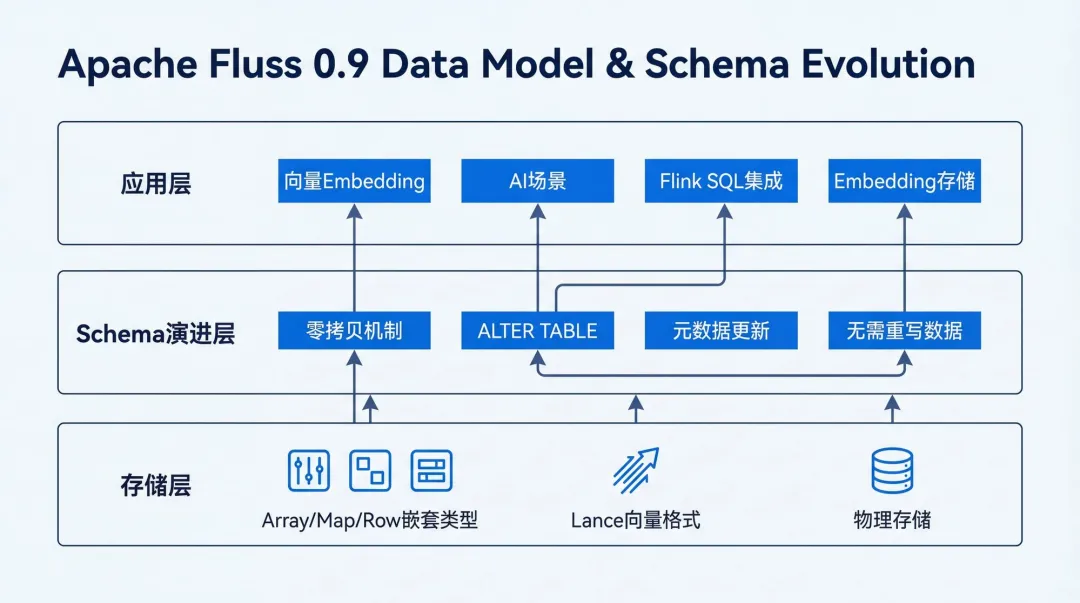
一、更丰富的数据模型与 Schema 演进
1. 复杂数据类型支持
Fluss 0.9全面强化了对复杂数据类型的支持能力。现在,像Array、Map以及嵌套Row这类深层嵌套结构,都能得到原生支持。关键在于,系统不再是简单地将它们当作不透明的二进制数据存储,而是能够逐层解析每个字段的类型和含义。这从根本上保证了数据写入的准确性和后续读取的精度。
此外,得益于对Lance格式的支持,Fluss现已能够胜任向量存储场景。用户可以直接使用ARRAY或ARRAY类型来存储Embedding向量,使其成为向量Embedding的可靠数据源。下游的向量引擎可以增量消费这些数据,从而高效地维护ANN索引,为AI应用铺平道路。
2. 零拷贝 Schema 演进
新版本引入了一项对生产环境极其友好的特性:支持通过追加新列的方式来变更表Schema,并且与Flink SQL实现了完全集成。这里的秘诀在于,Schema变更时,已有的数据文件完全无需重写,仅仅更新元数据即可。对于已有记录中缺失的新增字段,系统会自动将其解释为NULL;而新写入的记录则会立即包含新增列。
这种方式的好处显而易见:它彻底避免了因Schema变更导致的停机时间和昂贵的数据回填操作。对于那些需要长期稳定运行的流式管道而言,这无疑是一个巨大的福音。
二、存储层处理与语义增强
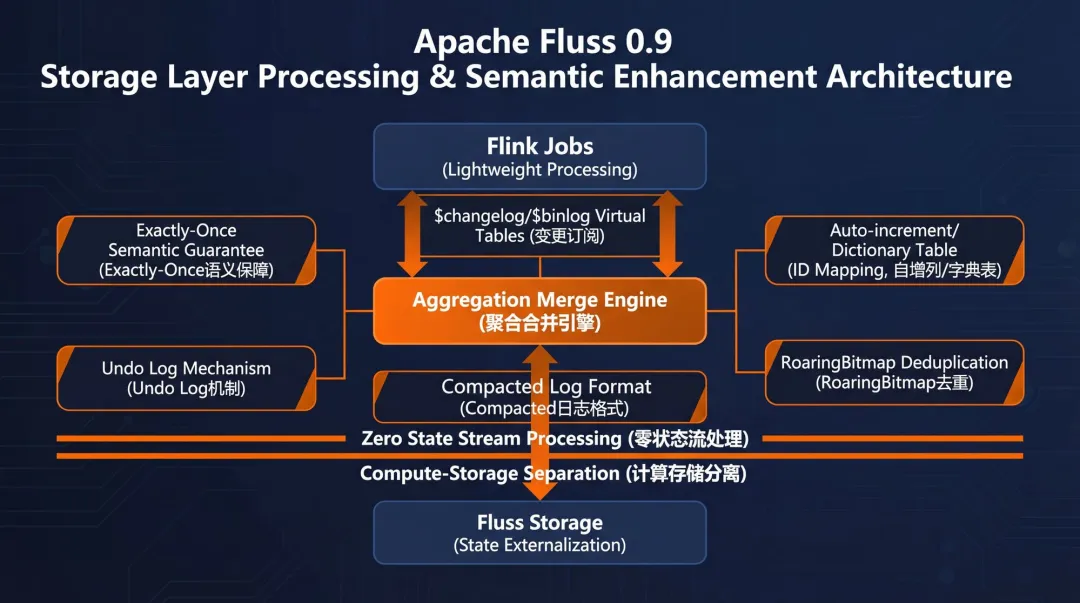
1. 聚合合并引擎
Fluss 0.9引入了一个重量级特性——聚合合并引擎。它的核心思想是将实时聚合计算从计算层“下推”到存储层来完成。在传统方案中,实时聚合严重依赖Flink状态来维护;而现在,聚合状态被外置到了Fluss中,使得Flink作业能够保持近乎无状态,大大减轻了计算引擎的压力。
更重要的是,该引擎提供了端到端的Exactly-Once语义保障。即使在故障恢复的场景下,也能确保数据的最终一致性。Fluss通过巧妙结合Flink的Checkpoint机制与自身的Changelog能力,在存储层实现了撤销日志机制。这意味着,在保障精确一致语义的同时,系统依然能维持高吞吐与低延迟的性能表现。
2. 自增列与字典表
新版本开始支持自增列,能够自动为记录分配唯一的、递增的数字ID。基于这个特性,Fluss进一步支持了字典表模式——可以将那些冗长的标识符(比如字符串或UUID)映射为紧凑的数字ID。
字典表在实时系统中应用非常广泛,典型场景包括ID的稠密化映射、去重计算等。再结合rbm32和rbm64这类基于RoaringBitmap的聚合函数,Fluss 0.9提供了一套高效的去重计算方案。它使得在海量数据流中实现实时去重统计成为可能,而无需在Flink中维护庞大的状态,从而提升了系统的整体稳定性和效率。
3. 变更数据订阅
为了更便捷地追踪数据变化,Fluss 0.9引入了$changelog和$binlog虚拟表,专门用于变更数据订阅。用户无需存储任何额外数据,就能直接访问表的元数据和变更历史。
具体来说,$changelog提供了单条变更记录的完整审计追踪;而$binlog则以Binlog格式呈现变更数据,同时提供了嵌套的before和after行结构,便于对比。这些虚拟表支持从最早、最新或指定时间戳等多种模式启动,这对于时间点恢复和AI场景下的模型回测至关重要。
4. Compacted 日志格式
针对全行读取这类特定场景(例如读取聚合结果表或向量表),Fluss 0.9引入了Compacted(行式)日志格式。这种格式将整行数据以紧凑的方式存储在一起。与默认的Apache Arrow列式存储相比,在全行读取的场景下,它能带来更高的I/O效率和更低的CPU开销,性能提升立竿见影。
三、生产运维能力增强
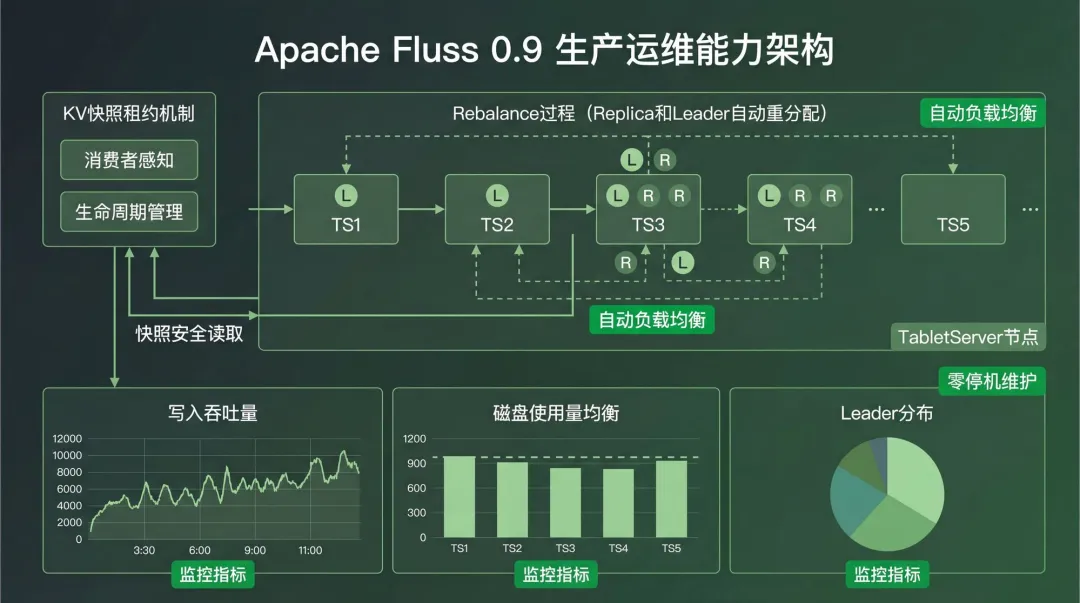
1. KV 快照租约
新版本通过支持KV快照租约机制,显著提升了基于快照读取的可靠性。在之前的版本中,快照清理仅由保留策略驱动,存在一种风险:当作业还在读取某个快照时,这个快照可能因为达到保留时限而被清理掉。引入租约机制后,快照的生命周期变得“消费者感知”,确保在作业的整个读取过程中,其所依赖的快照始终可用,避免了潜在的数据访问中断。
2. 集群 Rebalance
Fluss 0.9现在支持在多个TabletServer之间自动重新分配数据副本和Leader角色,从而实现数据和流量的负载均衡。整个Rebalance过程设计得非常平滑,集群的写入吞吐能够保持稳定。完成后,各节点的磁盘使用量、Leader数量和副本数量都会达到均匀分布的状态。这个特性极大地简化了日常的集群运维工作,也提升了在集群规模变更期间的业务稳定性。
四、生态与开发体验提升
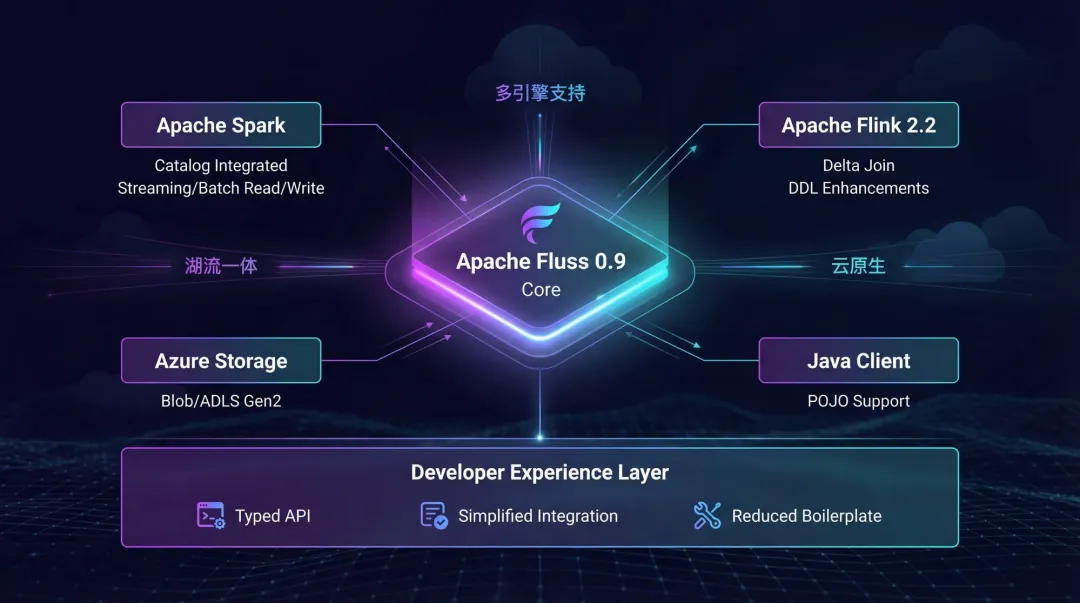
1. 多引擎支持
在生态集成方面,Fluss 0.9取得了扎实的进展:
Apache Spark:引入了Spark Catalog支持,实现了无缝的元数据管理,同时支持流式和批量读写。
Apache Flink 2.2:紧跟Flink最新版本,为Delta Join开启了更丰富的查询模式,并支持通过ALTER TABLE动态调整数据湖的新鲜度配置。
2. Azure 文件系统支持
通过新增的Azure文件系统插件,Fluss将其云原生存储能力扩展到了Microsoft Azure生态。现在,它可以支持使用Azure Blob Storage和Azure Data Lake Storage Gen2作为分层存储的后端,为用户提供了更多的云存储选择。
3. Ja va 客户端 POJO 支持
为了提升Ja va开发者的使用体验,Fluss现在支持POJO。开发者可以直接将表行数据映射到熟悉的Ja va类中,这大幅减少了样板代码,使得将Fluss集成到现有的Ja va微服务或应用程序中变得更加轻松、自然。
4. 升级与试用
对于考虑升级的用户,有个好消息:Fluss 0.9在网络协议与存储格式层面保持了高度兼容性,实现了客户端与服务端之间的完全双向兼容。当然,详细的升级步骤和注意事项,建议参考官方发布的最新升级指南。
目前,基于Apache Fluss打造的阿里云流存储产品已经完整支持了Fluss 0.9的全部功能,并开启了免费公测。在公测期间,单用户可免费使用2个集群,且单个集群的资源上限为80 Core。对于想要尝鲜和评估的企业与开发者来说,这无疑是一个绝佳的机会。
这就是Fluss 0.9 正式发布, 核心亮点都在这里了的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- A股PCB概念股集体下跌,南亚新材跌超7%
- 雷军亲临北京车展!小米汽车发布会揭秘新车型,逛展直播送福利
- 苹果新任 CEO 特努斯面临人才流失挑战芯片高管为何成为第二把手
- 《战国王朝》最新更新4月30日上线 新武器系统登场
- 八位堂推出 Retro 18 机械数字键盘 - Xbox 版:绿透配色 209 元
- 宝华韦健 Px8S2 头戴式耳机新增“藏金蓝”“晴漪蓝”配色可选 首发价 5399 元
- 硬件情报站第206期:一代经典卡RTX 3060 12GB或要复活 超频大神揭开RTX 5090烧接口真相
- 《最终幻想14》8.0资料片Evercold公布 支持PS4平台、2027年1月上线
- 《生化危机9》发售不到两个月 销量突破700万
- 《极限竞速:地平线5》PS5版销量已超500万








大家还在看
-
- 《异环》鬼火摩托获取教程 鬼火摩托怎么获得
-
26-04-25
-

- 《背包英雄》快速英雄成就解锁指南
-
26-04-25
-
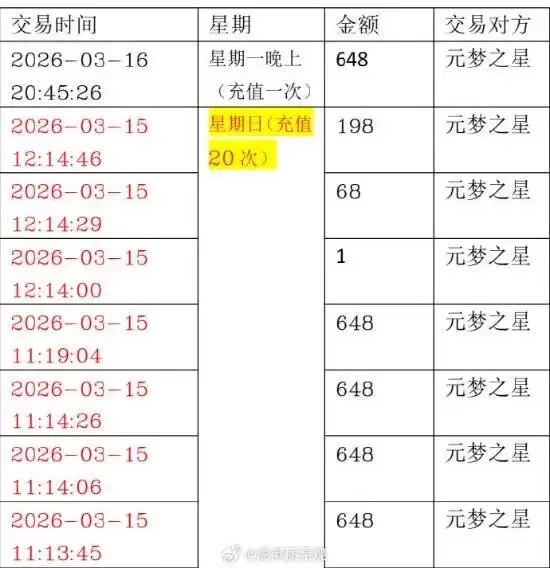
- 两女童游戏累计充值86次,金额超3万!腾讯:可退70%
-
26-04-25
-

- 金铲铲之战s17星神赛季爆料
-
26-04-25
-

- 面相学好玩吗 面相学玩法简介
-
26-04-25