图解 Linux I/O 模型:同步、异步、阻塞、非阻塞,一篇搞懂五种 I/O 模式
时间:26-04-25
一、先搞清楚两个维度
在深入探讨具体的I/O模型之前,我们必须先把两个最核心、也最容易混淆的维度彻底拆分开。很多人的困惑,根源就在于把这两个不同坐标轴上的概念混为一谈了。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
维度一:阻塞 vs 非阻塞(关注“等待数据时的姿态”)
这其实是在问:当数据还没准备好时,调用方在干什么?
- 阻塞:发起I/O调用后,如果数据没到位,调用方就老老实实“挂起”等待,什么也干不了,直到数据就绪。
- 非阻塞:发起I/O调用后,不管数据有没有,调用立刻返回一个结果(可能是错误码)。调用方不会被“卡住”,可以转身去处理其他任务。
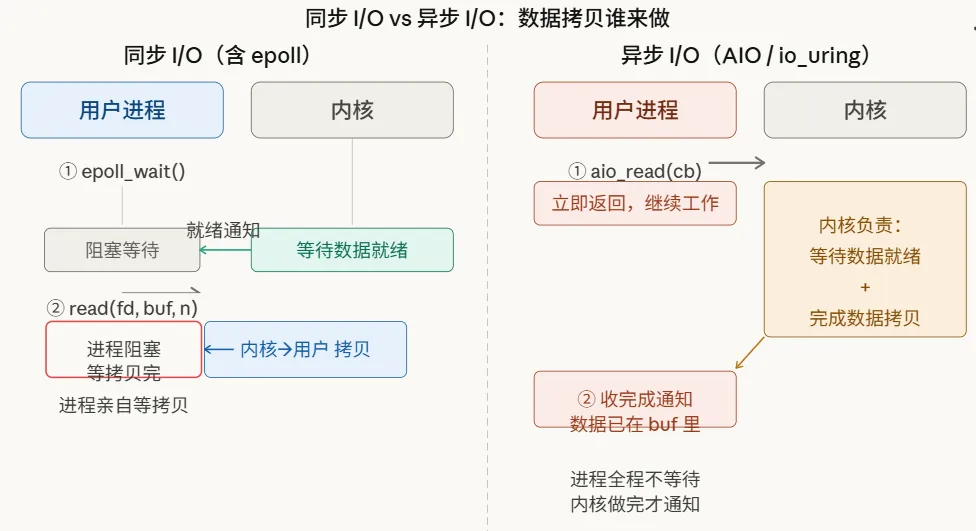
维度二:同步 vs 异步(关注“数据从内核拷贝到用户空间时,谁来做”)
这解决的是另一个问题:数据从内核缓冲区搬运到用户缓冲区这个体力活,谁来干?
- 同步:这个拷贝动作,必须由调用方自己动手完成。无论之前等待时是睡着还是醒着,最后这“临门一脚”你得亲自来。
- 异步:内核会包办一切。调用方只需要发起一个请求并提供一个目标缓冲区,内核会在后台默默完成数据准备和拷贝的全部工作,最后再通知你:“活儿干完了,数据在您指定的地方。”
这个区分点至关重要。举个例子,epoll为什么被归为同步I/O?因为epoll_wait只是告诉你“有数据到了”,但接下来你还得自己调用read(),亲手把数据从内核“搬”到用户空间。这个“搬运”过程,你是同步参与的。
记住这两个独立的维度,下面五种模型就能对号入座,一目了然。
二、五种 I/O 模型全景图
Linux系统为我们提供了五种经典的I/O模型,它们共同构成了处理I/O的完整工具箱。来看这张全景图:

这张图是理解所有I/O模型差异的钥匙,建议保存。五种模型的本质区别,其实就围绕刚才说的两点:等待数据时谁在等,以及拷贝数据时谁来做。
三、模型一:阻塞 I/O(Blocking I/O)
这是最古老、也最简单的模型。像read()、recv()这类系统调用,默认就是阻塞模式。
// 一个典型的阻塞读操作
char buf[4096];
int n = read(sockfd, buf, sizeof(buf)); // 数据没来?进程就在这里睡着,啥也干不了
// 数据来了,内核完成拷贝到buf后,read()才返回
printf("收到 %d 字节\n", n);在只需要处理单个连接的情况下,阻塞I/O简单直接,没什么问题。但麻烦出在多连接场景:一个线程一次只能read一个文件描述符(fd)。于是早期出现了“一个连接一个线程”的方案。然而,当连接数飙升,成千上万的线程带来的上下文切换开销,足以让系统不堪重负。
四、模型二 & 三:非阻塞 I/O + I/O 多路复用
非阻塞I/O的思路很直接:通过fcntl将fd设置为O_NONBLOCK。这样,read()调用就不会阻塞,如果数据没准备好,它立刻返回一个EAGAIN错误,然后你可以继续尝试。
但问题来了:如果单纯靠程序循环去“轮询”检查,CPU就会陷入空转,消耗100%的资源却干不了正经事,这显然不可接受。
于是,真正的解决方案出现了:将非阻塞fd与I/O多路复用机制结合使用。用一个系统调用(select/poll/epoll)同时监视成百上千个fd,当其中任何一个就绪时,才通知你去处理。这就像是一个高效的“门卫”,帮你盯着所有连接,有动静了才叫你。

I/O多路复用的核心优势正在于此:单线程管理海量连接。哪个连接有数据就处理哪个,没有就安静等待。这正是Nginx、Redis等软件能够用单线程或少量线程扛住超高并发的根本原因。
来看一个以epoll为例的代码骨架:
int epfd = epoll_create1(0);
// 注册需要监视的fd
struct epoll_event ev = { .events = EPOLLIN, .data.fd = sockfd };
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &ev);
struct epoll_event events[64];
while (1) {
int n = epoll_wait(epfd, events, 64, -1); // 阻塞等待,直到有fd就绪
for (int i = 0; i < n; i++) {
read(events[i].data.fd, buf, sizeof(buf)); // 关键一步:自己完成数据拷贝(同步)
handle(buf);
}
}请注意最后一步:epoll_wait告诉你“某个fd有数据可读了”,但把数据从内核空间拷贝到你的buf中,这个动作仍然需要你调用read()来完成。这就是为什么epoll被归类为同步I/O模型。
五、模型四:信号驱动 I/O
这个模型的思路有点特别:为fd注册一个SIGIO信号的处理函数。当数据就绪时,内核会发送一个信号通知你,你再去调用read()读取数据。
signal(SIGIO, sigio_handler); // 注册信号处理函数
fcntl(sockfd, F_SETOWN, getpid()); // 告诉内核:“通知我”
fcntl(sockfd, F_SETFL, O_ASYNC); // 开启异步通知
// ... 进程可以继续处理其他事情 ...
void sigio_handler(int sig) {
read(sockfd, buf, sizeof(buf)); // 数据就绪,但拷贝仍需自己动手(仍是同步)
}在等待数据阶段,进程是非阻塞的,可以处理其他事务。然而,在数据拷贝阶段,进程依然需要亲自调用read()——因此,它仍然属于同步I/O。
实际上,信号驱动I/O在工程实践中应用较少,因为信号处理函数本身存在诸多限制(如异步安全性问题),并且在并发极高时信号可能丢失。了解其原理即可,重点应放在其他更主流的模型上。
六、模型五:异步 I/O(真正的异步)
前面四种模型,无论等待阶段如何,在数据从内核搬到用户空间这个关键时刻,进程都需要“亲自”参与。而异步I/O则完全不同:
你只需要向内核提交一个请求:“帮我读数据,读完后放到我指定的缓冲区,全部搞定后通知我。” 然后你就可以完全放手,去做其他事情。内核会在后激进分子立完成数据等待和拷贝的全部工作,最后再通知你来取结果。
Linux早期的POSIX AIO(aio_read/aio_write)是异步I/O的一种实现,但存在一些限制,并未大规模普及。
真正让异步I/O在Linux上大放异彩的,是内核5.1版本引入的io_uring。它通过共享内存环形队列在内核和用户空间之间传递请求和完成事件,彻底避免了频繁的系统调用开销。其性能甚至能超越epoll,并且适用范围极广,涵盖了网络I/O、文件I/O等多种场景。
七、五种模型横向对比
(此处保留原文对比信息,通常以表格或列表形式清晰展示五种模型在阻塞/非阻塞、同步/异步维度的区别,以及各自特点。)
八、选型指南
面对这么多模型,该如何选择?这里有一个简单的决策路径:
连接数少(< 100),逻辑简单
└→ 阻塞 I/O + 多线程,代码最简单直观。
连接数多(面临C10K问题),追求高并发
└→ epoll(I/O 多路复用)+ 非阻塞 fd + 事件循环。
这是 Nginx、Redis、Netty 等高性能组件的核心模型。
追求极致性能(网络 + 文件 I/O 混合场景)
└→ io_uring(Linux 5.1+,现代内核推荐)。
需要跨平台支持
└→ 使用 libuv(Node.js底层)、libevent 等封装好的跨平台异步I/O库。九、高频面试题精析
Q:epoll 是同步还是异步的?
同步。 epoll_wait 只是通知你某个fd可读/可写了,但接下来,你必须自己调用 read() 或 write() 来完成数据从内核到用户空间的拷贝。这个拷贝过程需要进程同步等待其完成。真正的异步I/O,连这个拷贝动作都由内核在后台包办。
Q:非阻塞 I/O 和 I/O 多路复用的关系是什么?
它们是一对黄金搭档,常常配合使用。非阻塞I/O解决的是“调用不挂起”的问题,但单纯轮询会浪费CPU;I/O多路复用(如epoll)解决的是“高效监视大量fd,精准通知就绪事件”的问题。通常的模式是:用epoll监视fd,当epoll通知某个fd就绪后,再用非阻塞的方式去读写它(处理可能出现的EAGAIN),从而实现高效处理。
Q:select、poll、epoll 三者的核心区别?
核心区别在于性能和实现原理。select和poll每次调用都需要将完整的fd集合从用户空间拷贝到内核,返回后还需要遍历整个集合来查找就绪的fd,时间复杂度是O(n)。而epoll通过在内核维护一个红黑树来管理注册的fd(只需注册一次),并通过就绪链表直接返回有事件的fd,使得获取就绪事件的时间复杂度达到O(1)。连接数越多,epoll的性能优势越明显。
Q:io_uring 比 epoll 快在哪里?
主要优势在两点:第一,减少系统调用。epoll模式下,通知就绪后仍需调用read/write,每次都有用户态/内核态切换开销。io_uring通过共享内存环形队列批量提交和收割请求,极大减少了系统调用次数。第二,支持纯内核轮询。io_uring可以配置IORING_SETUP_SQPOLL标志,让内核启动一个专属线程来轮询提交队列,在某些场景下甚至可以做到提交I/O请求的零系统调用开销。
十、结语
最后,让我们回到最核心的那句话:阻塞/非阻塞描述的是“等待时的姿态”,而同步/异步描述的是“拷贝时谁来做”。这是两个独立且正交的维度。
理解了这一点,你就能从根本上厘清概念,准确回答“为什么epoll是同步的”、“select为何是同步阻塞”、“io_uring才是真异步”这些问题,而不再依赖于死记硬背。
这也解释了为什么Redis能够凭借单线程模型配合epoll,爆发出惊人的吞吐能力——当I/O多路复用被用到极致,一个线程就足以优雅地驾驭数万并发连接。
这就是图解 Linux I/O 模型:同步、异步、阻塞、非阻塞,一篇搞懂五种 I/O 模式的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-

- 据报道,大秘境额外拾取(Bonus Rolls)存在重复掉落问题
-
26-04-26
-
- 《异种航员2》游戏中期技巧分享-第3至4个月生存与进展指南
-
26-04-26
-

- Midnight Patch 12.0.5 全职业最佳虚空锻造额外投掷装备指南
-
26-04-26
-

- 《三国:百将牌》不删档版本常见问题FAQ
-
26-04-26
-

- 王者荣耀世界回血方法大全王者荣耀世界角色快速恢复生命值技巧
-
26-04-26