故障排除:磁盘 IO 突然飙升,一条命令找到罪魁祸首!
时间:26-04-25
异常现象:磁盘IO的“幽灵式”飙升
最近在技术社群里看到一个相当典型的线上问题:服务器的磁盘IO利用率突然周期性飙高,接近30MB/s,并且持续了数小时。有意思的是,CPU和内存的使用率却风平浪静,一切正常。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
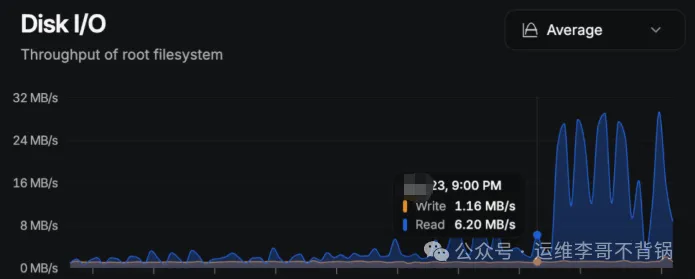
说实话,这类问题有时比CPU直接打满更让人头疼。CPU满载,你至少能快速锁定消耗资源的进程;而磁盘IO悄无声息地飙升,就像有个“幽灵”在后台持续作业,第一眼很难揪出元凶。不过,其排查思路一旦清晰,解决起来也相对直接。
从监控图可以清晰看到两个阶段:前期IO稳定在低位,后期则出现了规律性的高峰。这种持续、有节奏的抖动,通常指向三类可能性:计划任务(cron)中的批处理作业、程序日志的疯狂输出,或者就是代码逻辑出现了死循环,在不停地写入磁盘。
问题定位:是磁盘瓶颈,还是“话痨”程序?
第一步,我们需要确认问题的性质:到底是磁盘本身达到了性能瓶颈,还是仅仅有程序在“喋喋不休”地写入?这时,iostat命令就派上了用场。
执行命令:iostat -x 1,重点关注几个核心指标:
%util:磁盘利用率,判断是否被打满。await:IO平均等待时间,反映IO响应速度。tps:每秒IO请求数。rkB/s,wkB/s:每秒读写数据量。
根据当时的排查情况,虽然wkB/s(写速度)持续处于高位,但%util并未打满,iowait也不高。这说明了什么?结论很明确:磁盘本身的性能并非瓶颈,问题根源在于某个或某些进程正在持续进行大量的写操作。换句话说,磁盘不是“跑不动”,而是被“话痨”程序吵得没停过。
最终定位:揪出那个“写盘狂魔”
定位到具体是哪个进程在“搞破坏”,就成功了一大半。超过九成的此类IO问题,都可以用iotop这个利器来精准定位。需要注意的是,有些Linux发行版可能没有预装此工具,可以通过yum install iotop(针对CentOS/RHEL系)来安装。
使用命令iotop -o(参数-o表示只显示正在发生IO的进程),界面会清晰地列出所有活跃的IO进程。排查时的关键输出类似下面这样:
PID USER DISK READ DISK WRITE COMMAND
2526 root 0.00 B/s 5.00 MB/s ja va xxx.jar答案瞬间浮出水面。一个PID为2526的Ja va进程正在以约5MB/s的速度持续写入磁盘。结合“前两天刚更新过代码”这个时间点,几乎可以断定:这不是系统级问题,而是新上线的代码引入了Bug,导致产生了持续的、高频率的磁盘写操作,很可能是日志输出失控或陷入了写文件的死循环。
解决问题:修复与预防
定位到具体进程后,解决路径就非常清晰了:
- 紧急止损:首先通过
ps -ef | grep 2526再次确认进程详情,然后使用kill命令终止该问题进程,以快速恢复系统IO正常。 - 根因修复:将问题反馈给开发团队,修复导致死循环或日志疯狂输出的代码逻辑。常见的措施包括为日志输出增加频率限制、修复循环边界条件、检查不必要的同步写操作等。
- 验证效果:部署修复后的代码,并再次观察监控。如下图所示,IO利用率已恢复平稳,持续数小时的周期性飙高现象消失。
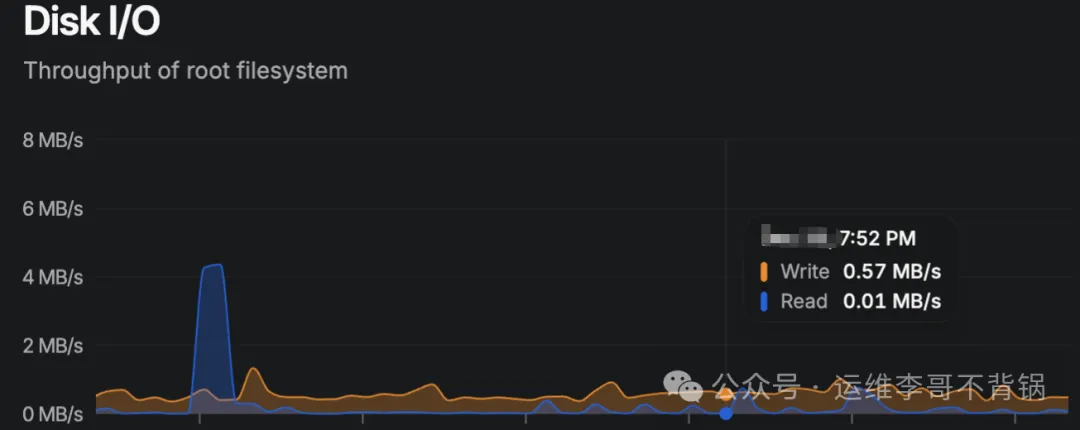
这次排查经历再次印证了一个运维常识:面对突发的资源异常,清晰的排查思路比盲目尝试更重要。从监控特征分析可能原因,到使用iostat判断问题维度,再到用iotop精准定位进程,这套组合拳能高效解决大部分“磁盘IO幽灵”问题。当然,最终还是要回归到代码质量和发布流程上,从源头减少此类问题的发生。
这就是故障排除:磁盘 IO 突然飙升,一条命令找到罪魁祸首!的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-

- 《剑侠世界》活动合集丨五一轻松游 多重福利畅享假期
-
26-04-25
-
- 《新寻仙》武器阵纹、天机更新攻略
-
26-04-25
-

- 《恐怖玩偶1游乐园》摩天轮图文攻略
-
26-04-25
-

- Escape Room:Aztec图文攻略(一)
-
26-04-25
-
- 《战舰世界》带来真正火力支援的序列礼包,现已上线!
-
26-04-25