踩坑实录:MySQL 服务器 CPU 爆高,元凶竟是 SELinux 的 setroubleshootd?
时间:26-04-25
一次由SELinux引发的MySQL性能“血案”与深度复盘
凌晨的监控告警总是格外刺耳。一个运行在CentOS上的核心MySQL数据库,CPU使用率突然飙升至800%以上,内存占用也直逼90%红线,随之而来的是业务接口的全面告急与超时。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
登录服务器,一行简单的top命令,揭示出的景象却足以让任何一位DBA心头一紧:

问题焦点一目了然:
PID为117647的mysqld进程固然压力山大,CPU占用113.0%,内存占用66.21%。但真正扎眼的,是下方那个用户为setroubleshoot+的进程(PID: 5869)。它以82.6%的CPU和17.27%的内存占用,以及高达7.3G的虚拟内存(VIRT),几乎在“喧宾夺主”。
这个setroubleshootd究竟是什么?简单来说,它是SELinux的“故障诊断医生”,专职负责收集和分析SELinux的访问拒绝(A VC)日志。
一、根因分析:为什么setroubleshootd会吃这么多资源?
首先确认了SELinux的运行状态:getenforce命令返回了Enforcing,表明强制访问控制策略正处于开启状态。

至此,问题的逻辑链条变得清晰:
- 大量SELinux告警爆发:MySQL的某些特定操作(例如访问特定数据文件、监听端口或创建线程)触发了SELinux的安全规则,导致系统产生了海量的A VC拒绝日志。
- 日志堆积与诊断过载:
setroubleshootd进程需要实时解析这些日志,并生乘人类可读的告警信息。当告警量在短时间内呈指数级增长时,这个诊断进程便会陷入疯狂的分析工作,CPU和内存资源消耗急剧攀升,其消耗甚至可能超过业务进程本身。 - 恶性循环形成:
setroubleshootd抢占大量系统资源 → MySQL性能进一步恶化 → 业务请求失败增多 → 可能触发更多非常规的SELinux告警 → 诊断进程负载再创新高。
一句话总结:问题并非出在SELinux机制本身,而是一个未经过恰当配置的SELinux,通过其诊断工具setroubleshootd,意外地转化为了系统性能的“杀手”。
二、影响评估
此次事件的影响范围远超单一数据库服务,波及了整个服务器的基础稳定性,主要体现在三个层面:
- 业务层面:MySQL查询响应时间从毫秒级骤增至秒级,部分读写请求超时,直接导致前端用户感知到页面加载缓慢或操作失败。
- 系统层面:内存与CPU资源被非业务进程大量侵占,系统负载(Load)飙升,一度濒临触发OOM(内存溢出)杀手机制,威胁到其他关键进程的存活。
- 安全层面:虽然SELinux仍在履行安全职责,但
setroubleshootd产生的高负载和海量泛化告警,反而会淹没真正关键的安全事件,使得运维人员难以甄别,造成“安全噪音”下的盲区。
三、解决方案:从临时止血到根治
1. 方案一:临时紧急止血(适合业务高峰期)
目标很明确:立即释放被占用的资源,为MySQL恢复运行创造条件。
# 停止setroubleshoot相关服务
systemctl stop setroubleshootd
systemctl stop setroubleshoot如果服务因故无法正常停止,可直接终止对应进程:
kill -9 5869执行后再次观察top,通常会看到MySQL的CPU和内存占用快速回落,业务响应逐渐恢复正常。
⚠️ 重要提示:此方法仅为权宜之计。服务器重启后,相关服务会再次自动启动,属于治标不治本。
2. 方案二:永久解决(推荐,从根源消除告警)
这是解决问题的根本之道:定位并允许MySQL正常运行所必需的操作,消除无效告警。
首先,需要查明具体是哪些MySQL操作触发了SELinux规则:
# 查看最近的MySQL相关A VC拒绝日志
grep mysql /var/log/audit/audit.log | tail -20
(1)生成并应用SELinux策略模块
使用audit2allow工具分析审计日志,自动生成允许这些操作的策略模块:
# 分析日志,生成规则模块
audit2allow -a -M mysql_local
# 将生成的模块安装到系统
semodule -i mysql_local.pp(2)验证并重启服务
再次检查/var/log/audit/audit.log,确认与MySQL相关的A VC拒绝日志已不再大量出现。随后,可以安全地重启之前停止的诊断服务:
systemctl start setroubleshootd
systemctl start setroubleshoot此时,setroubleshootd进程的资源占用将恢复至正常水平。
3. 方案三:临时关闭SELinux
如果时间紧迫,来不及深入分析规则,可以将SELinux切换至Permissive模式(仅记录而不阻止违规行为)。若生产环境安全要求允许,甚至可以考虑临时关闭。但务必注意,这仅是过渡方案。
setenforce 0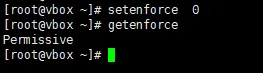
⚠️ 严重警告:此操作会完全解除SELinux的强制访问控制,仅在极端紧急情况下使用,生产环境绝不推荐长期保持此状态。安全要求高的环境,必须在问题处理后重新开启。
无论采用哪种方案,任何对SELinux策略的修改,都强烈建议先在测试环境中进行充分验证,以规避对线上业务造成不可预知的影响。
四、经验总结:给DBA的几点提醒
回顾这次事件,可以提炼出几个关键点:
首先,SELinux并非洪水猛兽。作为Linux内核的重要安全模块,它能有效遏制权限提升和恶意代码执行等风险。真正的挑战在于“正确配置”,配置不当的安全工具,其副作用可能远超其收益。
其次,高负载是表象,日志才是线索。setroubleshootd进程的异常资源消耗,本质上是底层安全告警未被及时处理、持续堆积的外在表现。定期审查和分析SELinux审计日志,主动解决合规性问题,才是治本之策。
最后,监控视野需要拓宽。完善的监控体系不应只盯着数据库本身的指标(如QPS、连接数、慢查询),还必须将系统级进程的资源使用情况、SELinux的运行状态与告警频率纳入监控范围,这样才能在问题萌芽阶段就捕捉到异常。
这次排查经历再次印证了一个核心理念:系统安全与性能优化从来不是非此即彼的对立面,它们完全可以在精细化运维的框架下协同共生。千万别让一个看似微小的SELinux配置疏漏,成为压垮整个高性能MySQL集群的那根稻草。
这就是踩坑实录:MySQL 服务器 CPU 爆高,元凶竟是 SELinux 的 setroubleshootd?的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-

- 天地劫幽城再临属性克制关系汇总
-
26-04-25
-
- 重返未来1999洛伦兹蝴蝶共鸣怎么摆放
-
26-04-25
-

- 《洛克王国世界》粉耳星兔怎样获得-粉星仔进化为什么有两种形态怎样进化成粉耳星兔
-
26-04-25
-

- 《红色沙漠》1.01.00版本更新内容详解-新增坐骑与操作优化
-
26-04-25
-

- 《奇异人生:重聚》流程成就解锁指南-详细步骤解析
-
26-04-25