千人千面,告别AI标准脸,阿里发布Wan2.7-Image
时间:26-04-25
告别“标准脸”与“色彩盲盒”:阿里Wan2.7-Image如何重塑AI生图体验
阿里巴巴正式发布图像生成与编辑统一模型Wan2.7-Image,精准切入当前AI生图领域的两大核心痛点:同质化的“标准脸”审美与不可控的“色彩盲盒”效应。该模型实现了真正的“千人千面”生成能力,能塑造出具有自然“活人感”的形象,并凭借创新的“调色盘”功能,为用户提供了前所未有的色彩精准控制。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
在功能层面,Wan2.7-Image覆盖了从文生图、图生组图到图像指令编辑与交互式编辑的全链路创作流程。其“文生图”能力在人类偏好盲测中已超越GPT-Image1.5及国内主流竞品。尤其在文本渲染准确性、照片级真实感以及世界知识表现等关键指标上,模型表现已接近Nano Banana Pro的水平。
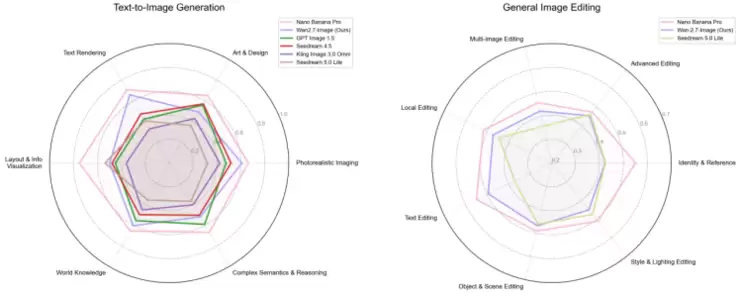
图说:Wan2.7-Image的人类偏好盲测评分位列国内第一。
捏出“活人感”:从骨相到眼眸的全面定制
为彻底解决“AI脸”同质化问题,Wan2.7-Image深度强化了虚拟形象捏脸功能。它支持从骨相轮廓、眼眸神态到五官细节的全方位参数化定制。用户仅需在提示词中指定脸型(如鹅蛋脸、圆脸、方脸)或眼部特征(如杏仁眼、深邃眼窝、丹凤眼),即可高效生成高度差异化的人物形象,实现“千人千面”的视觉效果。

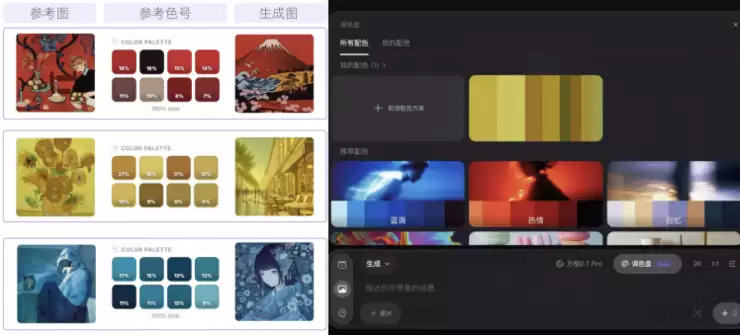
告别“色彩盲盒”:专业级调色盘来了
对于专业设计师、艺术家及商业应用而言,精准的色彩控制是刚性需求。Wan2.7-Image推出的“调色盘”功能,直接解决了传统AI生图色彩输出不稳定的痛点。用户可通过HexCode色值精确提取或输入参考图中的颜色及其占比。无论是马蒂斯画作的浓郁红色、梵高作品的明媚黄色,还是毕加索时期的清冷蓝色,均可作为配色参考,生成色调统一的图像。用户还能自由调控画面中颜色的数量与比例,实现完全自定义的配色方案。
印刷级文字渲染:超长文本不再“糊”
超长文本渲染是衡量AI生图模型能力的关键指标。Wan2.7-Image搭载的长上下文文本编码器,能有效解析超长序列信息,从而在渲染长段落文字、复杂表格及数学公式时达到印刷级精度。模型支持12种语言,最高可处理3K tokens的文本输入,足以直接生成整页A4篇幅的论文内容,解决了文字模糊、错乱或缺失的行业难题。

高效组图生成与精准交互编辑
Wan2.7-Image具备强大的组图生成能力,可一次性生成多达12张风格高度一致的图片。此功能极大提升了批量制作同风格系列图、PPT配图、分镜脚本、电商模特套图或多视角建筑渲染图的工作流效率。
模型的交互式编辑模块赋予了创作者像素级的最终控制权。用户可通过精准框选,在指定区域内添加、对齐或移动任何元素(包括Logo),实现意图的精准对齐,让图像修改变得直观且高效。

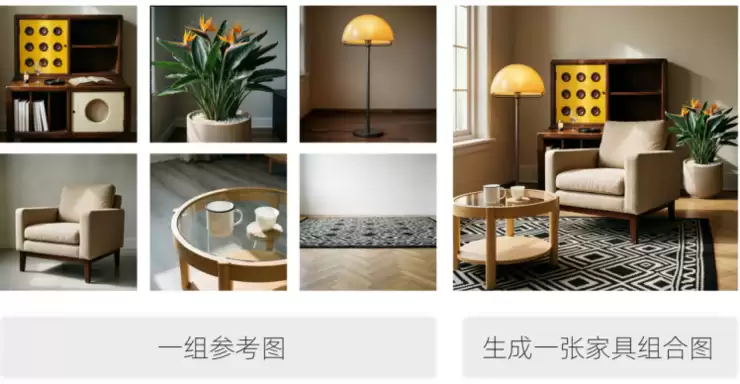
多主体一致性与丰富实用功能
在处理复杂场景时,Wan2.7-Image的多主体一致性功能支持输入最多9张参考图片,确保在制作合影、电影海报或家具组合图时,风格与特征保持高度统一。此外,模型稳定集成了镜头视角控制、光影处理、材质参考、照片修复、虚拟试衣等数十种实用图像编辑功能,让用户告别“抽卡”式的不确定创作体验。
技术突破:从“像素拟合”到“语义认知”
Wan2.7-Image的核心优势在于其“懂画”的语义理解能力。这源于模型架构与训练流程的多项关键技术突破。
训练数据方面,其超大规模异构数据底座不仅包含全域视觉素材,更整合了理解类数据。模型采用领先的生成与理解统一架构,通过共享隐空间实现高效的语义映射,使文字与画面的对应关系更直接。训练流程中引入的多模态指令(文字+图片),驱动模型实现了从“像素拟合”到“底层语义认知”的关键跨越。
在数据工程层面,团队基于图像布局、文字、光影、拍摄角度与用途构建了多维精细标注体系。结合分阶段训练策略与多任务优化,模型在长尾场景下仍能保持极高的生成稳健度。基于更大规模数据训练的Wan2.7-Image-Pro也已同步上线,在图像构图稳定性与语义理解精准度上表现更为出色。
赋能千行百业:从影视创作到电商营销
Wan2.7-Image的强大功能拥有广泛的应用场景。影视与短剧团队可利用其捏脸系统与分镜生成能力,低成本完成角色设定与特效预览。内容创作者可快速生成多种风格的封面图与穿搭展示图。电商领域,仅凭一张模特图即可裂变生成特写图与多场景卖点图,大幅降低拍摄成本。教育科研从业者能直接调用模型生成论文配图、信息图表乃至儿童绘本。针对新兴的“龙虾热”趋势,模型现已支持skill调用,全面解锁生成式AI的应用想象力。
目前,用户可通过https://tongyi.aliyun.com/wan/、wan.video 以及阿里云百炼平台体验Wan2.7-Image,千问App也即将完成接入。
(公众号:)
这就是千人千面,告别AI标准脸,阿里发布Wan2.7-Image的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- 今年火流星激增,“天空到处是乱飞的物体”!科学家激辩:应该不是外星人干的
- Meta盘前涨超1%!10亿美元数据中心项目启动,千岗就位
- “口袋哈苏”OPPO Find X9 Ultra亮相,第五代骁龙8至尊版赋能专业移动影像创作
- 程序员将被AI取代?梅宏院士:理性看待当前的热潮和炒作
- 蚂蚁百灵Ling-2.6-flash模型发布 定价每百万token0.1美元
- 当机器人伸出手……汉诺威工博会人机互动精彩瞬间
- 北京移动用户可享算力套餐
- 马斯克打算花600亿美元收购“00后”创办的Cursor,加码AI编程
- 42项高价值配置全系标配 别克至境E7正式上市并开启交付
- 坚守开源,深耕中国,奥芯明接待临港代表团








大家还在看
-

- 西山居《解限机》S4赛季5月26日上线,新机务组接棒重启
-
26-04-26
-

- 《星空》更加优越成就解锁指南
-
26-04-26
-

- 《星空》老妇美食成就解锁指南
-
26-04-26
-

- 《洛克王国世界》版本更新+资源获取+任务速通,一篇带你起飞!
-
26-04-26
-

- 《三国杀:武将觉醒》郭嘉锦囊搭配攻略
-
26-04-26