报告称谷歌搜索AI概览准确率约90%
时间:26-04-26
谷歌AI概览宣称90%准确率,但每小时潜在错误答案或超5700万条
《纽约时报》近期披露的数据显示,谷歌AI概览(AI Overviews)功能的官方准确率约为90%。这个数字看似可观,但结合谷歌每年超过5万亿次的搜索体量计算,结果便不容乐观:即便仅有10%的失误率,理论上每小时也可能产生超过5700万条错误答案,即每分钟接近100万条。这种规模化的潜在信息偏差,对搜索生态的可靠性构成了实质性挑战。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
第三方基准测试:准确率攀升,但“引证失准”问题恶化
AI初创公司Oumi利用SimpleQA基准对谷歌搜索进行了评估。基于超过4300次搜索的分析,其数据显示:去年10月搭载Gemini 2模型的搜索准确率约为85%;至今年2月,升级至Gemini 3模型后,准确率提升至91%。模型迭代带来了效率的显性增长。
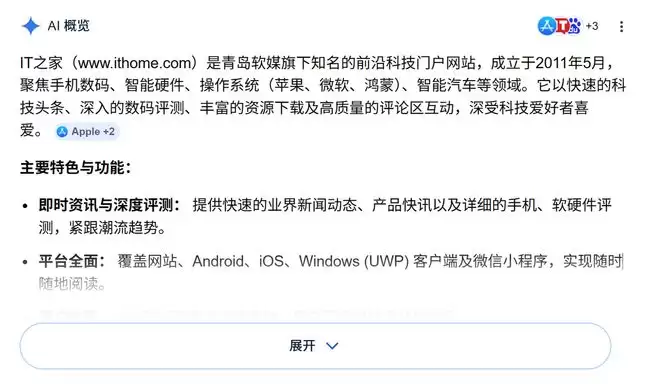
例如搜索IT之家,跳出的 AI 概览介绍
然而,评估中存在几个关键变量:Oumi的测试本身依赖AI工具,存在误差空间;谷歌AI概览对同一查询的响应内容存在波动。更值得关注的是,AI生成的概览文字与其下方引用来源信息“不匹配”的比例正急剧上升——该比例已从Gemini 2时期的37%增至Gemini 3的56%。
这种“引证失准”通常表现为两种形式:一是AI总结的内容存在事实错误,但所附链接却指向正确信息;二是总结主旨基本正确,却引用了包含细节错误的网页。这类似于一份技术报告结论正确,但支撑数据来源混乱,严重削弱结论的可信度。
内容易受操纵,且呈现页面内逻辑矛盾
研究进一步揭示了AI概览的脆弱性:其内容极易受到刻意植入信息的影响。有记者通过实验证实,发布一篇包含虚假陈述的博客后,次日谷歌AI概览便引用了该博客内容。这种机制为恶意信息操纵提供了可乘之机。
普通用户的直接体验更能说明问题。以用户斯蒂芬·潘瓦西的查询为例:搜索“摔跤手胡克·霍根是否去世”,AI概览明确回应“无可信报告显示霍根已去世”。但同一搜索结果页面下方,却显示一篇标题为“霍根之死谜团加深”的文章。AI的确定性断言与来源文章的暗示性标题形成直接冲突,导致用户陷入信息判断困境,严重损耗对AI生成内容的信任基础。
谷歌的回应与行业反思
针对Oumi的测试,谷歌发言人指出其方法可能未能反映真实、复杂的用户搜索行为。这一质疑确实触及了实验室测试与海量实际应用场景之间的评估鸿沟。
然而,测试方法论的争议并不能消解已暴露的核心问题:信息与源链接脱节、内容易受污染、页面内信息逻辑冲突。当AI承担起信息归纳与直接答案提供的角色时,其对准确性与一致性的要求远高于传统检索。每分钟近百万条潜在错误的理论推演,是一个明确的警示:在采纳AI摘要结论前,保持信息交叉验证的审慎习惯,仍是当前必要的操作守则。
这就是报告称谷歌搜索AI概览准确率约90%的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-
- 符文英雄竞技场第一名教你如何打造最强战力
-
26-04-26
-
- DNF据说这个称号很贵 坐等称号封装系统
-
26-04-26
-

- RNG战胜EDG成功复活 网友表示圣枪哥是最大罪人
-
26-04-26
-

- 古梦浮生好玩吗 古梦浮生玩法简介
-
26-04-26
-

- 《聪明开局吧》第53关捌怎么过-第53关捌找出9个常用字图文攻略
-
26-04-26