超越DeepSeek-V4,罗福莉交出小米最强开源模型,首日适配5家国产芯片
时间:26-04-28
模型技术细节公布,测评超越DeepSeek-V4
消息来得很快。就在刚刚,由小米罗福莉团队主导研发的MiMo-V2.5系列模型正式宣布开源,采用宽松的MIT协议,这意味着商用推理和二次训练都无需额外授权,门槛大大降低。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
▲MiMo-V2.5-Pro在Hugging Face的开源页面截图
其实,这个系列在几天前(4月23日)就已经开启了公测,包含MiMo-V2.5-Pro和MiMo-V2.5两款模型。它们的卖点很明确:更强的智能体(Agent)能力、高达100万Token的上下文窗口,以及大幅提升的Token处理效率。
而今天,随着模型权重全面开放,MiMo-V2.5-Pro的完整基准测试成绩也一并揭晓。根据小米公布的数据,该模型在GDPVal-AA(Elo)、Claw-Eval(pass^3)等多个关键评测中,表现已经超过了最新开源的DeepSeek-V4-Pro,甚至压过了发布不久的Kimi K2.6等主流闭源模型,实现了总体最佳。
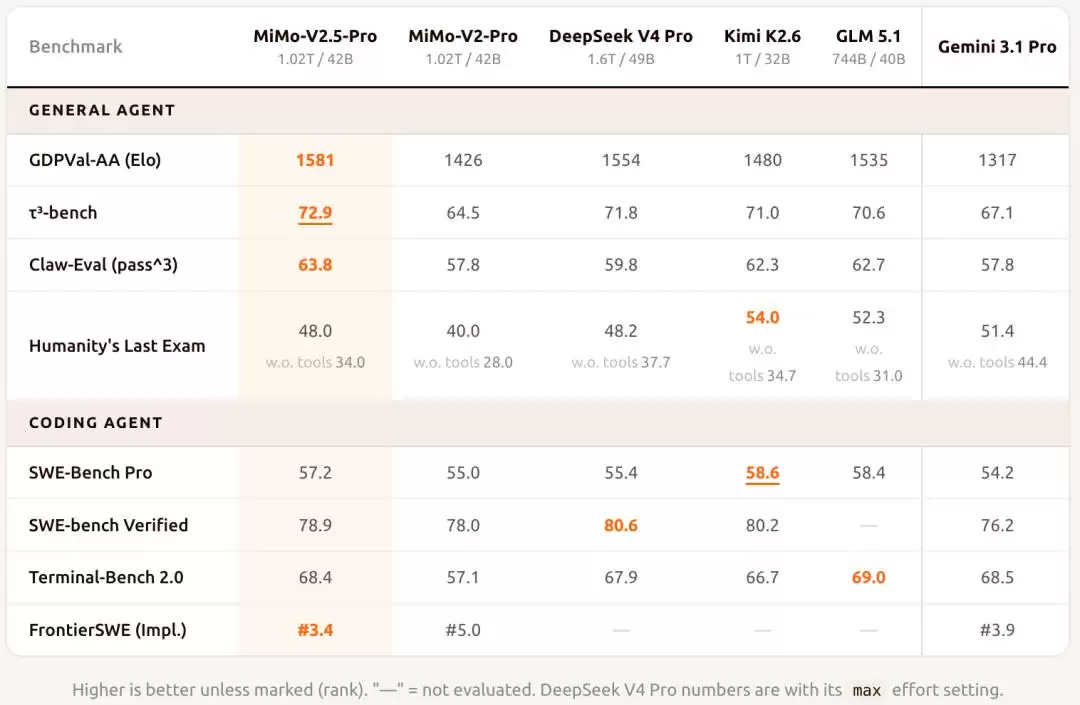
▲MiMo-V2.5-Pro的最新测评成绩
更值得玩味的是生态布局的速度。开源首日,小米就宣布MiMo-V2.5-Pro已完成与阿里平头哥、亚马逊云科技、AMD、百度昆仑芯、燧原科技、沐曦、天数智芯共七家芯片厂商的接入适配。同时,整个MiMo-V2.5系列也同步完成了对SGLang和vLLM这两大主流推理框架的“Day 0”适配,可谓“开箱即用”。
当然,光有技术和适配还不够,生态激活是关键。小米同步推出了“MiMo Orbit计划”,包含两大举措:一是“百万亿Token创造者激励计划”,承诺在30天内免费发放总计100万亿Token权益;二是“Agent生态共建计划”,目前已与OpenCode、Hermes Agent、KiloCode等智能体框架厂商展开了合作。
模型权重合集:
https://huggingface.co/collections/XiaomiMiMo/mimo-v25
更多细节参考模型Blog:
https://mimo.xiaomi.com/index#blog
百万亿Token计划申请网址:
https://100t.xiaomimimo.com/
01. 参数架构与训练路径解析
根据最新公开的模型卡信息,小米目前最强的MiMo-V2.5-Pro是一款参数规模达到1.02万亿的混合专家模型,其中激活参数为420亿。它基于混合注意力架构打造,相比前代,在通用能力、复杂软件工程和长序列任务处理上都有显著提升。
具体来看,它继承了MiMo-V2-Flash的混合注意力机制和多标记预测设计。局部滑动窗口注意力和全局注意力以6:1的比例交错使用,窗口大小为128个Token。这种设计在长上下文场景下效果显著,通过可学习的注意力池偏置,能将键值缓存的存储空间压缩近7倍,同时性能不打折扣。而那个轻量级的多标记预测模块,采用密集前馈网络,原生集成在训练和推理流程中,使得输出吞吐量提升了大约三倍,也加速了强化学习的部署效率。
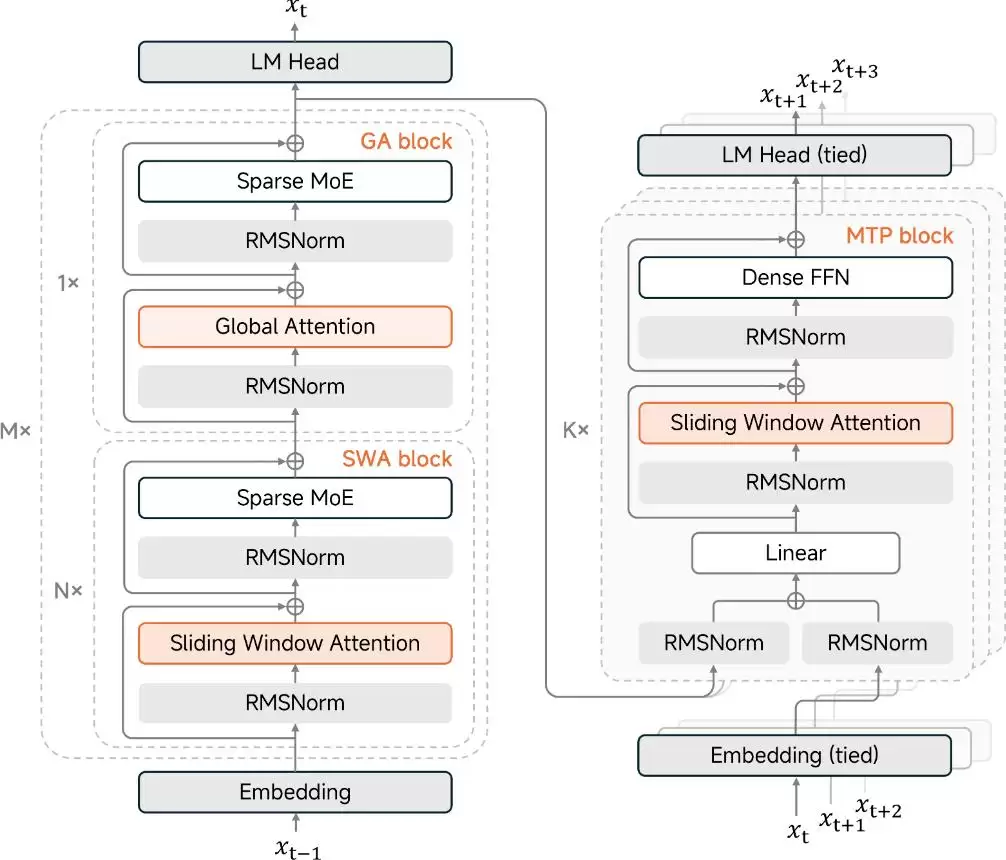
▲MiMo-V2.5-Pro的模型架构及训练过程
训练过程则体现了清晰的阶段性策略。预训练阶段使用了27万亿Token,采用FP8混合精度,原生序列长度32K,并扩展至100万上下文。后训练则遵循一个三阶段范式:首先是监督式微调,在精选的数据对上建立基础的指令跟随能力;接着是领域专精训练,让不同的教师模型通过针对特定领域的强化学习进行优化,覆盖数学、安全、工具使用等;最后是多教师策略蒸馏,让单个学生模型在各位专精教师的Token级指导下进行学习,最终将所有能力融合到一个统一的模型中。
再来看看标准版的MiMo-V2.5。这是一个3100亿参数的稀疏MoE模型,激活参数为150亿,在48万亿Token上进行了训练。它的语言主干同样继承了混合滑动窗口注意力机制,并搭载了自研的预训练视觉和音频编码器,这两类编码器通过轻量化的投影模块实现了跨模态融合。
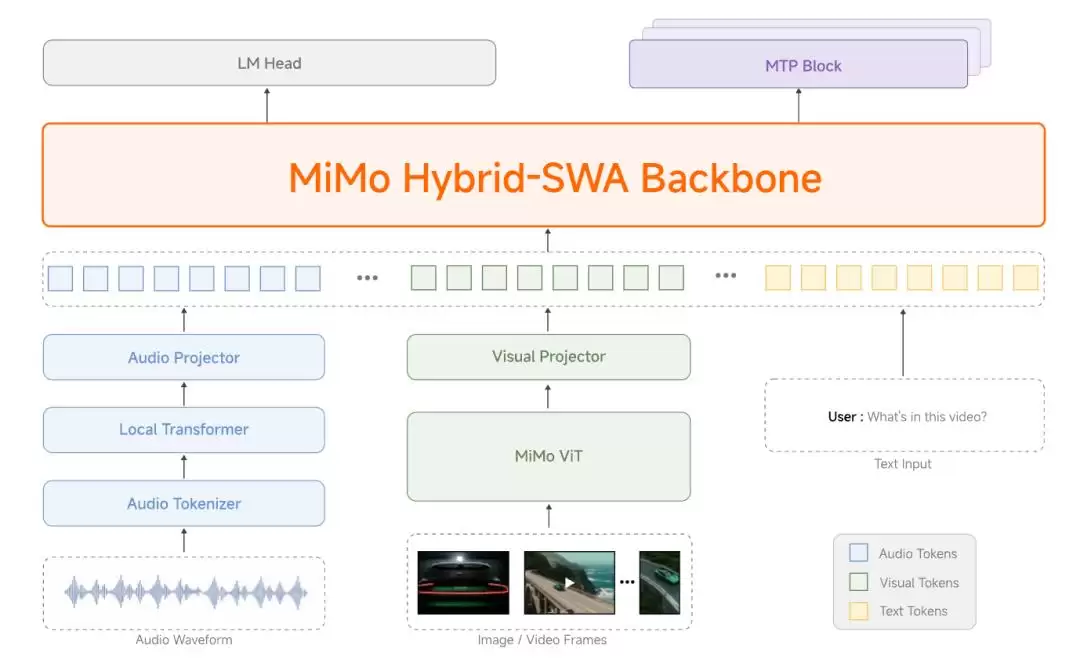
▲MiMo-V2.5架构
它的训练路径更为细致,分为五个阶段:从多样化的文本预训练开始,搭建语言模型主干;接着进行投影层预热,实现多模态对齐;然后依托高质量跨模态数据开展大规模多模态预训练;第四步是监督微调与智能体后训练,同时将上下文窗口从32K逐步扩容至100万Token;最后通过强化学习与多目标偏好蒸馏,进一步强化模型的综合能力。
那么,实际效果如何?从公布的测评结果看,MiMo-V2.5在Claw-Eval Text、Terminal-Bench 2.0、SWE-Bench Pro等多个评测集上,成绩大幅超越了DeepSeek最新发布的DeepSeek-V4-Flash。
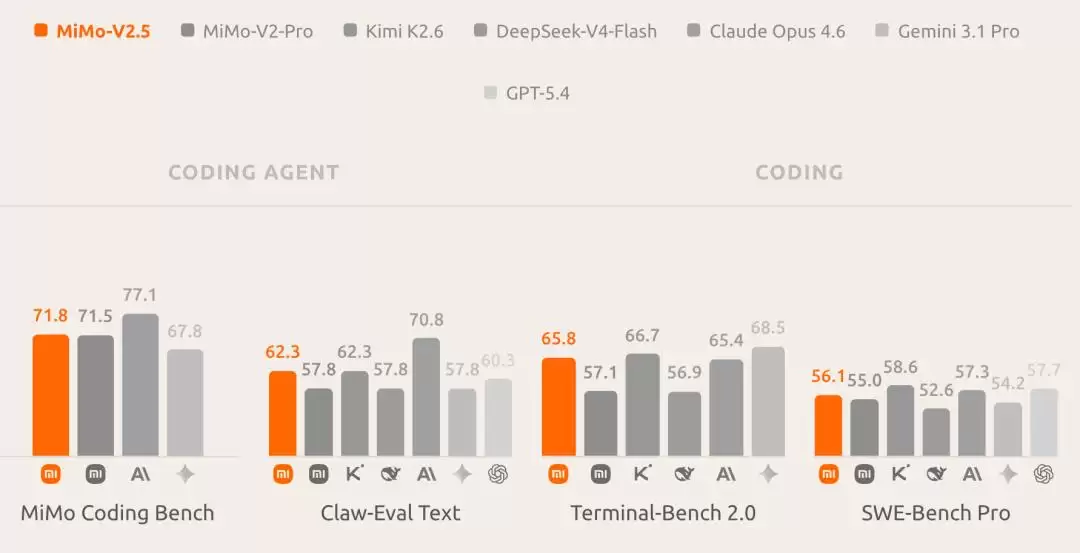
▲MiMo-V2.5最新测评情况
02. 开源首日,完成阿里平头哥沐曦等7家芯片厂商适配
模型性能是一方面,能否快速、高效地部署落地则是另一场硬仗。小米在开源首日就亮出了一份覆盖主流芯片的适配清单,这无疑是向市场展示其生态决心和工程化能力。
具体适配情况如下:
阿里平头哥:基于真武810E芯片及全栈自研AI软件栈实现了深度适配。
亚马逊云科技:基于Trainium2芯片与Neuron SDK+vLLM推理框架完成深度适配,实现了“开源即全球可用”的首日适配。据悉,下一代3nm制程的Trainium3将进一步释放模型性能。
AMD:依托其ROCm开源软件栈,提供了Day-0适配及全面优化支持。
百度昆仑芯:通过底层算子优化与软硬件协同加速,保障模型稳定高效运行。
燧原科技:基于自研驭算TopsRider软件栈深度优化,并在燧原L600计算卡上完成了全量适配。
沐曦:基于曦云C系列GPU及全栈自研MXMACA软件栈,实现了从Triton语法到沐曦GPU指令集的端到端原生支持。
天数智芯:实现了Day 0级别的深度适配。
除了芯片生态,在推理框架层面,MiMo-V2.5系列也同步完成了对SGLang和vLLM这两大主流框架的Day 0适配,为开发者减少了部署阻力。
03. 免费发放100万亿Token,已与Hermes Agent等合作
技术开源和硬件适配搭建了舞台,而要真正激发生态活力,还需要吸引开发者“登台唱戏”。小米的“MiMo Orbit计划”正是为此而来。
计划包含两部分,首先是“百万亿Token创造者激励计划”。简单说,就是小米准备在30天内,面向全球AI开发者免费发放总计100万亿Token的调用权益,赠完即止。这无疑是吸引开发者和初创公司尝鲜、构建早期用例的一剂强心针。
该计划采用申请制,成功通过审核的开发者最高可获得“Max档位Token Plan”,包含16亿Credits,价值约659元软妹币。活动窗口期从北京时间2026年4月28日零点持续到5月28日零点。
另一部分是“Agent生态共建计划”。这项计划面向全球的智能体框架团队,提供专项支持,包括为合作框架提供MiMo Token的限免支持,并参与和赞助框架平台举办的AI Hackathon等共创活动。目前,小米已与OpenCode、Hermes Agent、KiloCode等多家Agent框架厂商展开了深度合作。
04. 结语:多款国产开源模型“亮见”交锋
纵观近期动态,大模型行业的开源竞赛正在进入新阶段。模型与国产及国际芯片的“Day 0”适配,已从值得宣传的亮点,逐渐变为参与竞争的刚需。这意味着,下一阶段的竞争焦点,将不可避免地转向推理效率和实际部署成本。
与此同时,像百亿级Token免费激励、与Agent框架生态共建这类举措,清晰地反映出行业重心正在迁移——从单纯地“拼参数、刷榜单”,转向更实际地“拼应用、建生态”。
值得注意的是,小米MiMo-V2.5-Pro在多项基准评测中直接对标并超越了DeepSeek-V4-Pro,这无异于在开源赛道上发起了一次正面“亮见”。这种高水平的直接竞争,对于整个行业而言是件好事,它有望倒逼技术快速迭代,加速推理成本的下探,并最终提升智能体在真实场景中的任务完成率。国产大模型的开源战场,好戏才刚刚开始。
这就是超越DeepSeek-V4,罗福莉交出小米最强开源模型,首日适配5家国产芯片的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章








大家还在看
-
- 《新惊天动地》常规服丨14周年庆典空降专属神秘福利,各位勇士速来围观参与
-
26-04-28
-

- 龙魂旅人布伦希尔德角色详解
-
26-04-28
-

- 《和平精英》家园名字怎么修改-家园名字修改指南
-
26-04-28
-

- 《和平精英》花圃怎么解锁-花圃解锁指南
-
26-04-28
-

- 《和平精英》SS13赛季团队模式怎么换队长-转让队长的具体步骤
-
26-04-28