人工智能大模型是什么意思,为什么叫大模型?底层逻辑与架构
本文大纲
一、大模型的物理本质:基于深度学习的核心网络架构解析
二、“大”的量化标准:参数规模与数据体量的技术临界点
三、规模效应引发的质变:从专用模型到通用智能的范式转移
四、核心基础设施:算力集群与分布式训练的技术实现
图源:AI生成示意图
一、大模型的基础物理定义
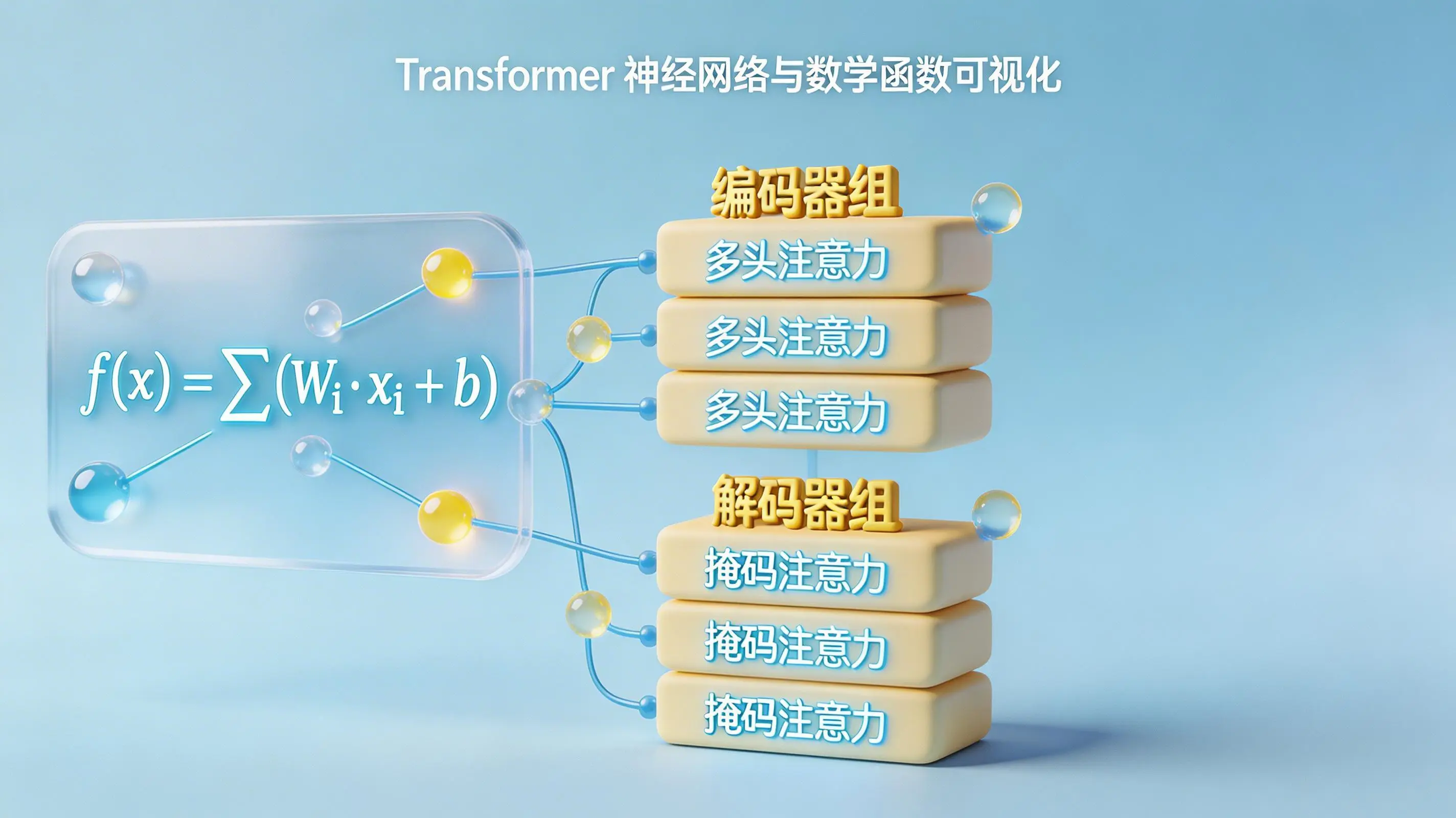
大模型常被过度神秘化。从技术内核看,其本质是一个由海量参数构成的复杂数学函数,当前技术路线主要基于Transformer架构实现。
它的运作机制与传统程序逻辑截然不同。大模型不执行预设的“if-then”规则,而是作为一个概率预测引擎,通过分析训练数据中的统计规律,推断序列中下一个最可能的元素——无论是文本token还是图像patch。
这定义了其“基础模型”的核心地位。它本身并非最终应用,而是一个提供通用智能能力的底层引擎。通过标准化的API接口,向多样化的下游任务输出能力。明确这一技术栈定位,是理解其商业价值与应用边界的关键。
图源:AI生成示意图
二、“大”的具体量化指标
“大”是一个可量化的技术指标,主要体现在参数规模与训练数据体量两个维度上的指数级突破。
参数是神经网络中神经元连接的权重值,决定了模型的知识容量与推理能力。传统模型的参数规模通常在百万至千万级别,而当代大模型的参数量已进入百亿至万亿范围。这是数量级的根本差异。
训练数据体量同步激增。大模型的预训练通常需要消化数万亿token的文本语料,涵盖网页、学术文献、代码等多种信息源。
参数如同模型的“神经突触”。参数量级越大,模型能建模的特征关系就越复杂,知识表示的维度也越高。这是其实现复杂认知任务的物理基础。

图源:AI生成示意图
三、规模带来的核心质变
规模的扩张并非简单的线性增强,而是触发了能力范式的根本性转变,即“涌现”现象。
当模型参数量突破百亿级临界点后,会突然展现出小规模模型不具备的复杂能力,如多步推理、上下文深度理解、指令泛化等。这类似于物理系统中的相变,是规模达到阈值后产生的质变。
由此带来了“通用人工智能”的雏形。传统AI模型是高度垂直的“窄AI”,而大模型展现出强大的跨任务泛化能力。同一套模型权重,无需结构改动即可处理翻译、编程、内容生成、逻辑分析等异构任务。这种“统一模型”的范式,正在重新定义AI应用的开发与部署方式。

图源:AI生成示意图
四、底层技术支撑条件
支撑大模型训练与部署的,是一套极其苛刻的硬件与工程体系,构成了极高的技术壁垒。
训练阶段需要巨大的算力投入。通常需要由数千张高性能GPU/TPU组成的集群,进行长达数周或数月的分布式并行训练,涉及海量的张量运算与内存交换。
推理部署同样面临挑战。由于模型参数量庞大,完整加载至单卡显存往往不可行。主流方案是通过云端API提供服务,或对模型进行量化、剪枝、蒸馏等压缩优化后,再进行边缘侧部署。强大的分布式计算基础设施,是大模型得以存在的物理前提。
总结
我们从技术本质、量化指标、能力涌现及基础设施四个层面,系统剖析了大模型的物理内涵。它是以Transformer为代表的深度神经网络,在参数量与数据量达到临界规模后形成的通用智能基座。
规模的指数级增长触发了“涌现能力”,使其获得了跨领域的任务泛化与复杂推理特性,从而成为驱动下一代软件的核心智能组件。
对于企业而言,接下来的核心课题是如何将这类百亿级参数的云端智能能力,安全、稳定地集成到现有业务流中。市场已有解决方案,例如实在Agent,它原生集成了通义千问、DeepSeek等多个主流模型,并通过私有化安全网关,允许业务人员通过自然语言指令直接调度企业内部系统与数据,为构建企业级智能自动化提供了可行的工程路径。