Databricks推出AiChemy多智能体AI 加速药物研发关键环节
Databricks推出药物研发AI系统AiChemy,早期研发效率提升60%以上
最近,全球数据与AI平台厂商Databricks在行业内投下了一颗“重磅冲击波”——正式发布了面向药物研发领域的多智能体AI系统,AiChemy。这套参考架构的核心价值,在于能打通药企内部私有研发数据与外部公开科研数据集之间的壁垒。结果呢?它成功将药物研发早期的靶点识别、化合物评估这些关键环节的平均耗时,硬生生缩短了60%以上。这无疑为整个生物制药行业如何规模化、标准化地应用AI技术,提供了一个极具参考价值的全新方案。
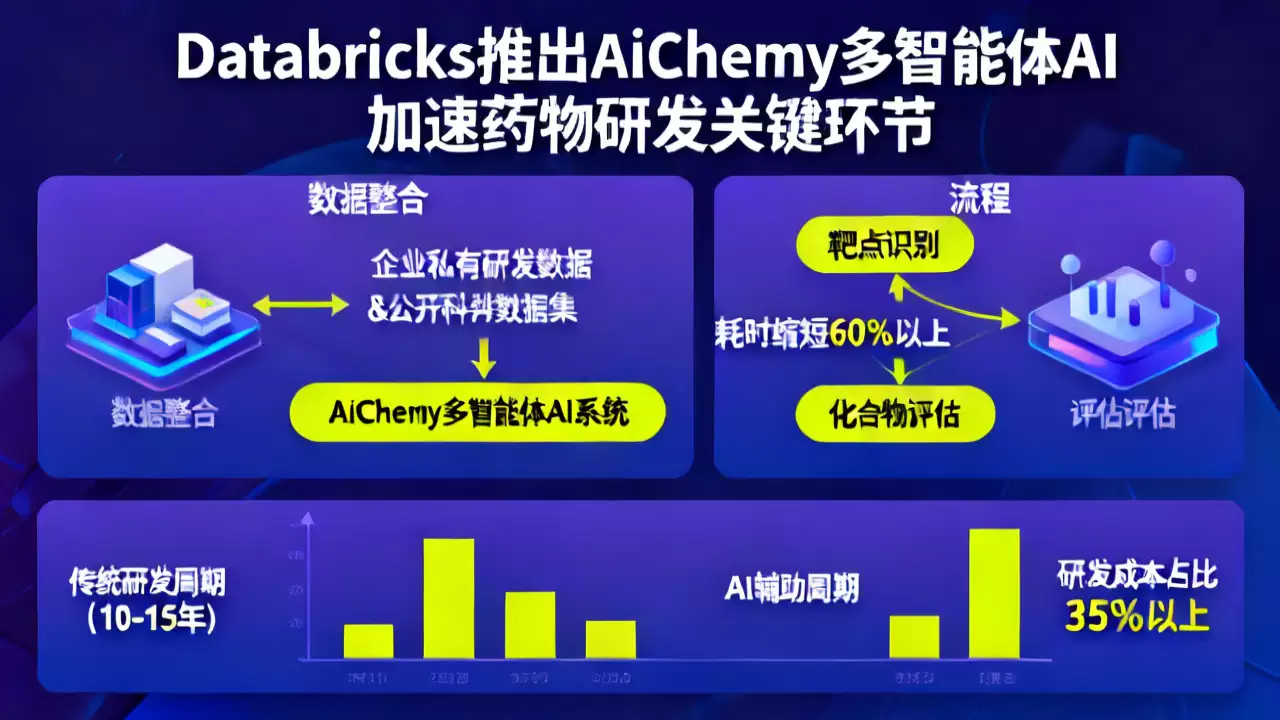
众所周知,新药研发是条漫长而昂贵的征途。一款创新药从最初的靶点发现到最终获批上市,平均要耗费10到15年的光阴,以及超过13亿美元的巨资。而其中,仅仅是早期的靶点筛选和候选化合物评估这两个环节,其成本占比就高得惊人,达到了总研发费用的35%以上。可以说,谁能在这两个“烧钱”的阶段提效,谁就握住了降本增效的命门。
过去几年,AI技术确实已经渗透到药物研发的各个环节,但痛点依然尖锐。市场上大多数工具都是“单点突破”型的,往往只能处理单一来源或类型的数据。这就导致了一个尴尬的局面:药企内部宝贵的实验记录、临床数据等私有资产,与海量的公开科研数据库(如蛋白结构库、学术论文)之间,始终存在难以逾越的鸿沟。数据不通,预测的准确性自然大打折扣,普遍不足60%,使得很多AI工具最终只能停留在“纸上谈兵”,难以真正融入实际的研发流水线。
那么,AiChemy这套多智能体AI参考架构,又是如何破局的呢?关键在于它碘伏了传统的单模型思路,转向了“团队作战”模式。你可以把它想象成一个高度专业化、分工明确的AI研发小组:其中一部分智能体,专门负责对接和解读药企内部的非结构化私有资料,比如实验室笔记、临床试验数据;另一部分智能体,则化身“科研情报员”,专职调取和分析公开的蛋白结构、科研文献等公共资源。这还没完,团队里还设有专门的“质检员”智能体,负责对来自不同渠道的数据进行交叉验证,确保信息的真实可靠。最终,这个AI小组协同输出的是结构化、高可信度的结果,比如靶点匹配度评分、化合物毒性预测,这些都能直接用于支撑研发团队的决策。
更值得一提的是,AiChemy在部署上展现了极大的灵活性。它无需企业对原有的数据系统进行“伤筋动骨”的大规模改造,就能实现不同格式数据的兼容与读取。这一特性,将其适配新环境的效率提升了足足60%,相比现有同类方案优势明显。这对于IT预算和人才相对有限的中小型药企来说,无疑大幅降低了引入先进AI工具的门槛。
好的架构,终究要靠实践来检验。目前,已有包括辉瑞、默沙东这样的跨国制药巨头在内的3家大型药企,以及12家生物科技初创公司,参与了AiChemy的内测。反馈回来的数据颇具说服力:在使用该系统后,早期靶点识别的周期从行业平均的6个月,大幅压缩到了1个月左右;而候选化合物评估的准确率,更是从普遍不足60%,跃升至82%。这些数字背后,意味着实实在在的时间和资金节约。
据Databricks相关负责人的透露,AiChemy的潜力远不止于制药。未来,其能力框架计划拓展到农业育种、新材料研发等同样需要处理海量、多源异构科研数据的领域。其目标是成为一个能够赋能多种基础科研的通用型AI架构,为更广泛的科学发现之旅提供坚实的底层支撑。这盘棋,下得可不小。