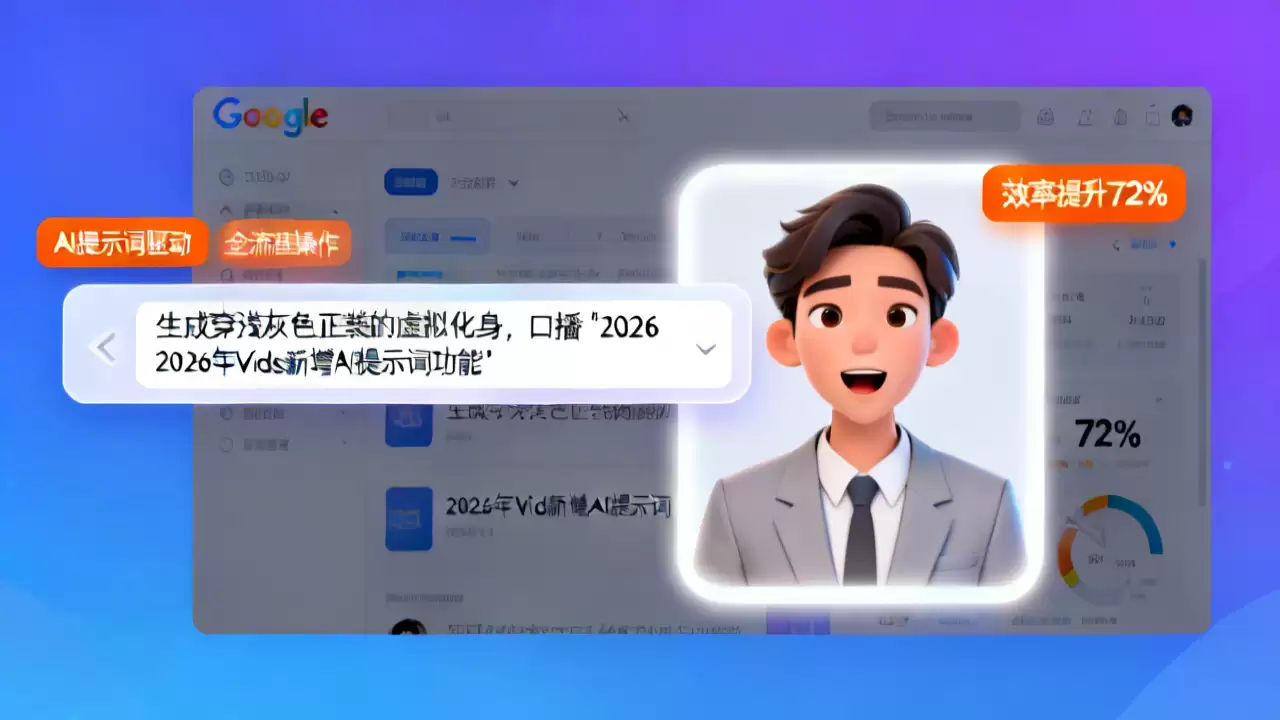
谷歌Vids新增AI提示词功能 可直接操控虚拟化身制作视频
谷歌Vids 2026年4月更新:AI虚拟化身重塑企业视频创作
2026年4月,谷歌Workspace核心组件——视频制作工具Vids完成了一次战略性迭代。本次更新的核心是推出由AI提示词驱动的虚拟化身生成器。用户通过输入自然语言指令,即可全流程完成数字人形象设计、动作编排与专业口播合成。谷歌内部测试显示,该功能将商业口播视频的制作效率平均提升了72%。目前,此功能已对所有Vids付费订阅用户开放。
解决职场核心痛点:从耗时数日到分钟级产出
对于企业内部的培训、宣导、产品说明等视频内容,制作流程历来冗长:协调发言人档期、租赁拍摄场地、进行后期剪辑与修改,成本与时间消耗巨大。谷歌Vids此次的AI虚拟化身更新,直接针对这一低效工作流,旨在将其彻底革新。
实际操作极为直观:在Vids创作面板中,用户只需输入一段描述性指令。例如:“创建一位身着深蓝色商务套装的男性虚拟化身,背景为现代简约的办公室,请他以沉稳专业的语调阐述本季度网络安全政策的五大要点。”系统将在60秒内生成包含匹配形象、场景、语音及精准口型同步的完整视频片段。
若需调整,直接向AI发出后续指令即可。例如:“将背景切换为数据可视化大屏,并将语速调整为中等。”整个过程无需视频剪辑专业知识,用户可在极短时间内迭代出符合品牌规范的商用视频成品。
聚焦企业级市场:确立差异化竞争壁垒
当前AI视频生成领域,多数工具侧重于艺术化视觉特效与风格化处理。谷歌Vids则明确将虚拟化身功能锚定于企业办公与沟通场景,解决的是高频、刚性的生产力需求。
市场数据支撑了这一方向:2025年,全球企业对专业化口播视频的需求量同比增长了137%,但仅有不足两成的企业配备有专属视频团队。谷歌的竞争优势在于,将Vids深度集成于Workspace生态。用户生成的AI视频可一键嵌入Google Docs、Slides及Meet记录中,实现了创作、协作与分发的闭环,显著提升了产品粘性与护城河。
核心引擎:Gemini多模态模型的垂直应用突破
这一流畅体验依赖于谷歌最新的Gemini 1.5 Pro多模态大模型作为技术基石。从文本指令到生成协调一致的3D形象、动作、语音与唇形,要求模型具备顶尖的跨模态理解与生成能力。
此前,谷歌已在Gemini的迭代中将3D内容生成的精细度提升了40%。本次Vids虚拟化身功能的上线,标志着该技术正式进入规模化商业应用阶段。这也预示着一个明确趋势:多模态AI的应用正从通用对话,加速向视频制作等垂直专业领域纵深发展。
演进路径:个人化数字分身与创作民主化
据谷歌产品路线图,Vids未来将支持用户上传个人形象,创建专属的数字分身。此举将极大拓展应用场景,覆盖内部培训、标准化产品解说、个性化客户沟通等多个维度。
行业分析指出,AI视频工具的持续进化正在重塑内容生产范式。未来,无需专业技能的普通员工,仅通过精准的提示词工程,即可产出过去依赖专业团队完成的高质量视频内容。这必将重构企业内容生产的成本结构与人力配置。对企业而言,实现高效、低成本的视觉化沟通,正迅速从竞争优势转变为生存必需。