还在乱用MySQL Query Cache?其为何从性能神器到历史尘埃
时间:26-04-24
一、query_cache到底是做什么的?
说起MySQL的query_cache,很多老DBA和开发者对它感情复杂。它本质上是一个内置的“结果缓存器”,设计初衷非常直接:把SELECT查询的完整结果存到内存里。这样一来,当后续出现一模一样的查询请求时,数据库就能跳过解析、优化、执行这些繁琐步骤,直接从内存里把结果“掏”出来还给客户端。目的很明确,就是为了节省时间,给数据库减负。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
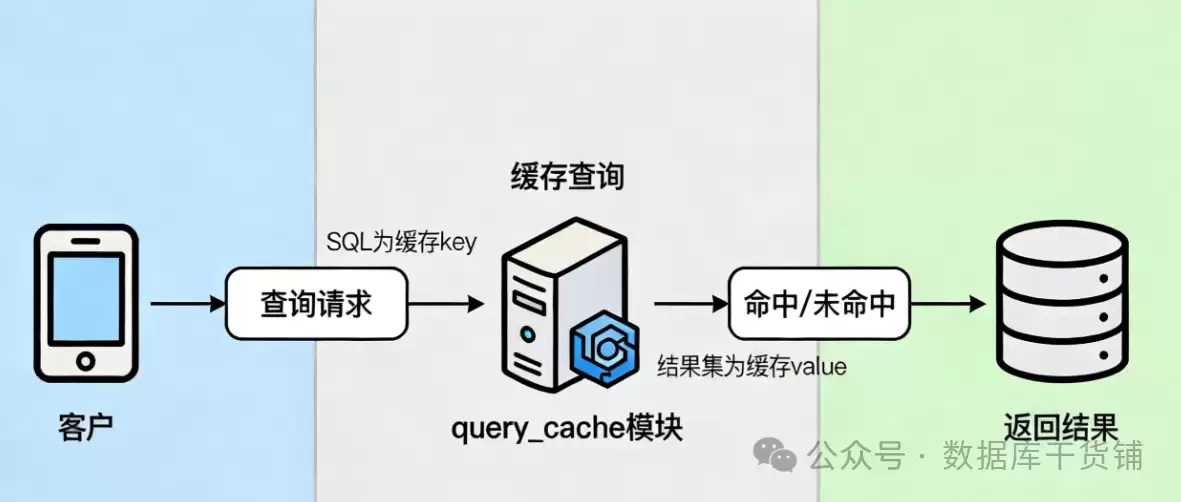
想象一个典型的电商场景:某个爆款商品的详情页,每天被访问上万次,背后对应的SQL可能就是一句简单的SELECT * FROM goods WHERE id=10086。如果没有缓存,每次点击都意味着数据库要老老实实地去磁盘找数据、解析SQL、执行查询,重复劳动效率低下。一旦开启了query_cache,第一次查询的结果就会被“记住”,后续所有访问同一商品的请求,都能瞬间拿到结果,速度的提升是立竿见影的。
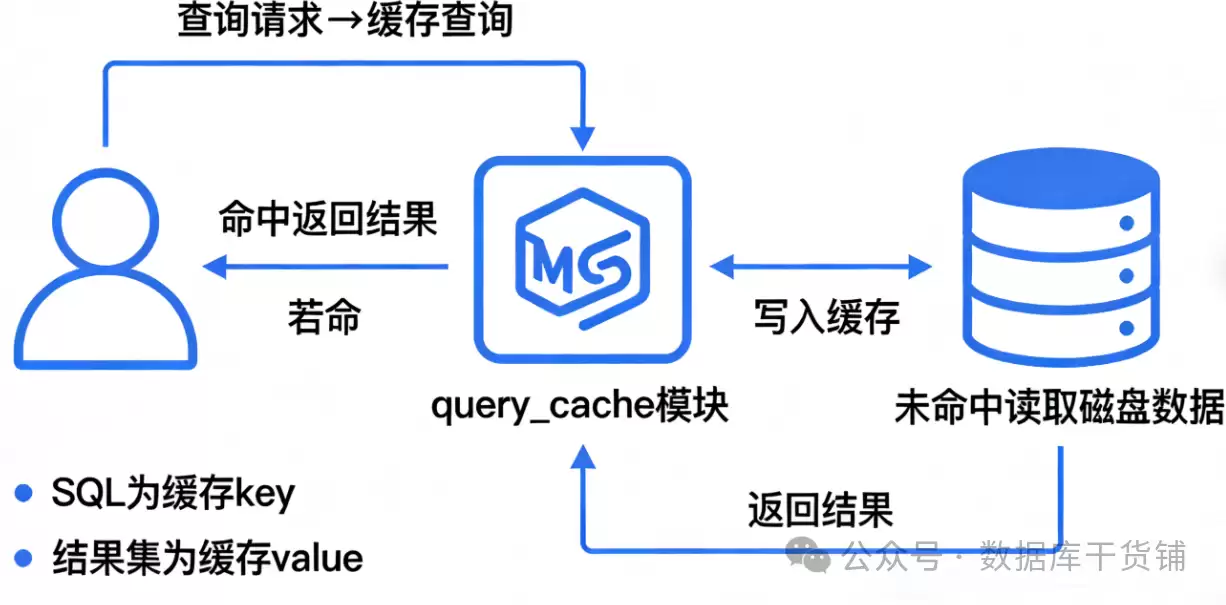
它的工作流程可以概括为四步:
- 客户端发来一条SELECT语句。
- MySQL服务器先不去执行,而是转头去query_cache里“翻找”,看看有没有一字不差的SQL和它对应的结果。
- 如果找到了(缓存命中),皆大欢喜,直接把缓存结果返回,后续所有步骤全部跳过。
- 如果没找到(缓存未命中),那就只能走常规流程:解析、优化、执行,拿到结果后,不忘把这条SQL和它的结果“配对”存进缓存,以备下次之需。
听起来很美好,对吧?但这里埋着一个关键伏笔:query_cache的命中条件,苛刻得近乎不近人情。它缓存的是SQL语句和结果集的键值对,并且要求SQL必须“字节级完全一致”。这意味着,大小写、空格、甚至一个不起眼的注释有任何差异,都会被它判定为两条不同的查询,从而导致缓存失效。比如select * from user和SELECT * FROM user,在它看来就是两码事。这种机械式的匹配规则,成了它日后被诟病的重要原因之一。
二、为什么MySQL8.0要彻底取消query_cache?
既然能优化查询,为什么在最新的MySQL 8.0里反而被一刀切地移除了呢?答案其实不复杂:在当今高并发、读写频繁的互联网业务场景下,query_cache的设计已经显得格格不入,弊远大于利,被淘汰是技术演进的必然结果。具体来说,主要有以下四个硬伤。
1.缓存失效太频繁,命中率极低
这是query_cache最致命的缺陷。它的缓存失效策略是“表级”的:只要对某张表执行了任何写入操作(INSERT、UPDATE、DELETE,甚至ALTER),那么这张表相关的所有缓存条目都会被无条件地清空。举个例子,用户表里有1000条查询被缓存着,这时候哪怕只更新了其中一条记录(UPDATE user SET age=25 WHERE id=1),整个用户表的1000条缓存瞬间就灰飞烟灭了。

反观现在的业务系统,绝大多数都是读写混合型。比如电商的商品表,每秒可能面临上百次查询,同时也有几十次库存更新或状态修改。这就让query_cache陷入一个尴尬的循环:刚缓存好的数据,可能下一秒就因为一个写操作被清空;系统不得不频繁地重新缓存,命中率自然惨不忍睹。在很多写入频繁的系统中,query_cache的命中率低到可以忽略不计,反而平添了检查缓存的开销。
2.全局锁竞争,拖慢高并发性能
query_cache内部使用了一个全局互斥锁来管理所有缓存操作。无论是查询缓存、插入新缓存还是清空缓存,都需要先拿到这把锁。这就意味着,在高并发场景下,大量线程会堵在“抢锁”这个环节上,容易引发线程阻塞和CPU使用率飙升,反而成了性能瓶颈。
可以设想一个极端情况:一个热门接口每秒承受1000次查询。如果开启了query_cache,这1000个请求很可能在锁等待上耗费大量时间,导致整体响应变慢。不少DBA都有过这样的体验:关闭query_cache后,数据库的吞吐量不降反升。根本原因就在于,省去了锁竞争的开销,查询路径反而更顺畅了。
3.命中条件太苛刻,实际复用率低
前面提到字节级一致的要求,这在实际开发中几乎是一个无法完美满足的条件。开发人员书写SQL的习惯差异、ORM框架(如MyBatis)自动生成的SQL在格式上的微小调整(比如末尾多个空格、添加了调试注释),都会导致同一条逻辑的SQL在文本层面产生差异,从而无法命中缓存。
这种“吹毛求疵”的匹配机制,使得query_cache的实用价值大打折扣。很多时候,它占用了宝贵的内存,却因为这些细微的格式问题而无法有效服务,形同虚设。
4.维护成本高,与现代缓存方案脱节
query_cache的内存管理机制比较僵化。其缓存大小是固定的,调整参数往往需要重启数据库实例,并且会导致所有缓存预热失效。同时,频繁的缓存失效和更新容易产生内存碎片,降低内存使用效率。
更重要的是,随着Redis、Memcached等专业分布式缓存的成熟与普及,query_cache的优势已被全面替代。这些外部缓存方案支持更精细的缓存控制、更高的吞吐量、灵活的失效策略以及分布式扩展能力,远比MySQL内置的这个“简陋”缓存强大和灵活。MySQL官方也意识到,与其继续维护这个日益鸡肋的功能,不如将开发资源投入到InnoDB引擎优化、更智能的查询优化器等更有价值的方向上。
总而言之,query_cache更像是一个为“纯只读”理想场景设计的功能,完全无法适应现代动态、高并发、读写交织的互联网应用需求。它在MySQL 8.0中的退场,是一次果断而正确的技术取舍。
三、如何确认一条SQL是否走了query_cache?
首先必须明确一个前提:MySQL 8.0及以上版本已经彻底移除了query_cache相关功能。 因此,在这些版本中讨论缓存命中毫无意义,即便在配置文件中写下相关参数,启动时也会收到“未知系统变量”的报错。

以下内容主要针对仍在使用MySQL 5.7及更早版本的环境。在实际工作中,可以通过以下几种方法来验证SQL是否命中了查询缓存。
1.如何确定是否走缓存了?
在MySQL 5.7等尚支持query_cache的版本中,确认缓存状态和命中情况是日常运维的一部分。下面介绍几种直接可用的方法。
方法1:查看query_cache相关系统变量,确认缓存是否开启
第一步永远是先确认缓存功能是否真的开启了。执行以下命令:
show global variables like 'query_cache%';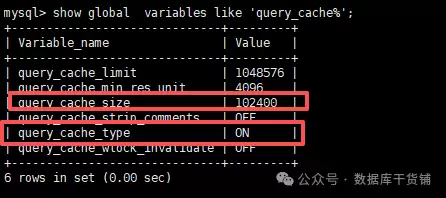
在返回的多个变量中,最需要关注两个:
- query_cache_type:缓存模式。0(OFF)代表关闭;1(ON)代表开启(除非SQL明确指明
SQL_NO_CACHE);2(DEMAND)代表按需开启,只缓存那些带有SQL_CACHE提示的查询。 - query_cache_size:分配给缓存的内存大小(单位字节)。如果这个值是0,那么即使
query_cache_type设为ON,缓存也实际上没有生效。
只有同时满足query_cache_type非0且query_cache_size大于0,query_cache才处于真正的工作状态。
方法2:用EXPLAIN分析,查看Extra字段
这是非常直观的一种方法。在目标SQL前加上EXPLAIN前缀然后执行,重点观察结果中的Extra字段。
- 如果
Extra字段显示“Using cache”,说明这条SQL可以命中缓存(注意:EXPLAIN本身不会触发实际缓存,这里只是表明优化器判断该查询可以走缓存)。 - 如果显示“Using where; Using cache”,则说明查询带有WHERE条件过滤,并且会利用缓存。
- 如果完全没有“Using cache”字样,那就意味着这条SQL不会走缓存(原因可能是缓存未开启、SQL不符合缓存条件,或者包含了非确定性函数等)。
方法3:查看缓存命中状态,验证实际命中情况(建议,最靠谱)
前两种方法更多是判断“可能性”,而查看状态变量则可以验证“实际发生”的命中情况。执行以下命令:
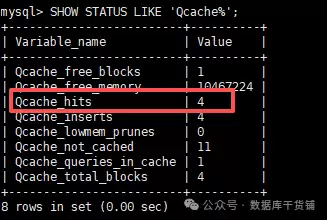
show status like 'Qcache%';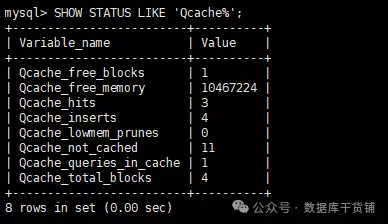
在输出的状态变量中,重点关注这三个:
- Qcache_hits:缓存命中总次数。每当有查询成功从缓存获取结果,这个值就会加1。
- Qcache_inserts:向缓存中插入新结果的次数。查询未命中而执行后,结果被存入缓存时,此值加1。
- Qcache_lowmem_prunes:因内存不足而从缓存中淘汰的旧条目数。如果这个值增长很快,说明分配的
query_cache_size可能不够用。
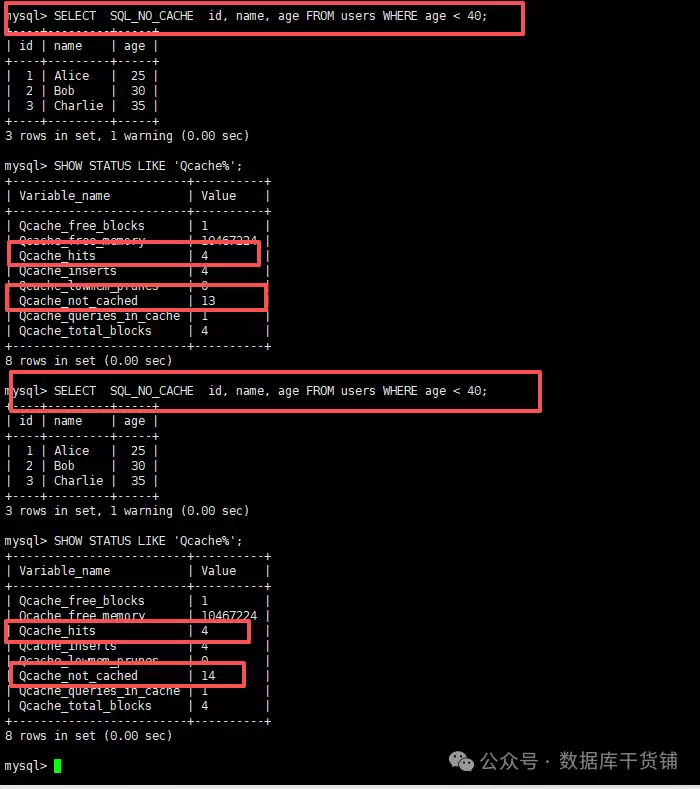
实际操作时,可以采用“前后对比法”:
- 首先执行
SHOW STATUS LIKE 'Qcache%';,记录下当前的Qcache_hits值(假设是3)。 - 接着执行你想要测试的目标SQL,例如:
SELECT id, name, age FROM users WHERE age < 40;。 - 再次执行
SHOW STATUS LIKE 'Qcache%';,查看Qcache_hits值。
如果该值增加了(比如从3变成4),说明刚才的查询命中了缓存;如果没变,则说明是未命中,走的是正常执行路径。
2.即使开启缓存也不会命中的场景
很多人在开启缓存后发现效果不佳,常常是因为踩中了以下这些“坑”。了解它们有助于在兼容版本中合理规避(仅适用于5.7及之前版本):
- SQL中包含了非确定性函数,例如
NOW(),RAND(),CURRENT_DATE()等。因为每次调用结果都可能不同,所以这类查询不会被缓存。 - 查询涉及临时表、存储过程、自定义函数,或者查询的是
INFORMATION_SCHEMA、PERFORMANCE_SCHEMA这类系统数据库。 - SQL语句中显式使用了
SQL_NO_CACHE提示,例如:SELECT SQL_NO_CACHE id, name FROM users;。这明确告诉数据库不要缓存此结果。 - 查询返回的结果集太大,超过了
query_cache_limit参数设置的单条结果大小限制(默认1MB)。 - 一个容易忽略的点:如果查询返回的结果是NULL值,query_cache默认也不会进行缓存。
四、总结
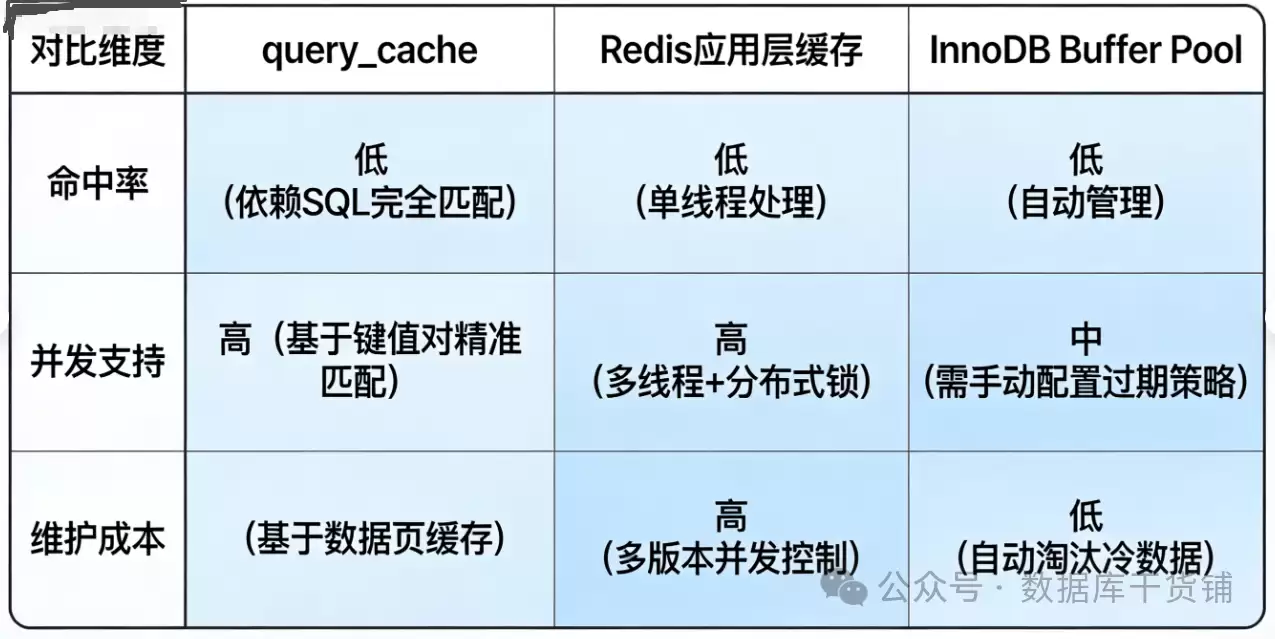
MySQL 8.0移除query_cache,绝非功能上的倒退,而是一次聚焦核心的性能优化。它促使我们放弃那个低效且笨重的内置缓存,转向更现代、更高效的解决方案。在当下的技术选型中,我们完全无需再纠结于query_cache,替代方案已经非常成熟:
- 应用层缓存:采用Redis、Memcached等专业的缓存中间件。它们能提供更细粒度的缓存控制、更高的并发吞吐能力、灵活的失效策略以及分布式支持,是目前最主流的缓存实践。
- 数据库自身优化:这才是提升MySQL性能的根本。专注于编写高效的SQL、建立合理的索引、并充分利用InnoDB的Buffer Pool(用于缓存数据页和索引页)。
- 本地缓存:对于访问频率极高且极少变更的静态数据(如系统配置),可以考虑使用Caffeine、Gua va Cache等本地缓存库,实现纳秒级的访问速度。
最后划一下重点:如果你的项目仍在使用MySQL 5.7或更早版本,请谨慎评估是否开启query_cache。对于纯只读或极少更新的静态表场景,可以尝试;但对于读写混合、高并发的业务,关闭它往往能获得更好的性能。至于MySQL 8.0及以上的用户,直接忘掉query_cache这个概念吧,把精力投入到真正能带来性能提升的优化手段上,才是明智之举。
这就是还在乱用MySQL Query Cache?其为何从性能神器到历史尘埃的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- 人工智能赋能教育减负增效钉峰会圆满举行
- 苹果宣布下调中国App Store佣金率 “苹果税”迎来新调整
- AI智能体社交网络Moltbook卖身Meta,创始人只靠AI助手没写一行代码
- OPPO Find N6配置曝光汇总:全球最平整折叠屏+2亿哈苏影像,3月17日发布
- 首发哈苏2亿超清四摄!OPPO Find N6影像配置官宣
- 东郊有约app如何使用-东郊有约app的使用方法
- 苹果折叠屏iPhone加速量产:12GB LPDDR5X内存敲定,三星成主要供应商
- 腾讯电脑管家如何设置信任软件-腾讯电脑管家设置信任软件的教程
- 三号动漫app如何登录-三号动漫app怎样进行登录
- 微信如何开启深色模式-微信深色模式开启的具体步骤








大家还在看
-
- 梦幻西游怎么查看剩余点数剩余点数有什么用
-
26-04-25
-
- 梦幻西游怎么查看剩余点数剩余点数有什么用
-
26-04-25
-
- 问道宠物转换道具的方法是什么怎么操作
-
26-04-25
-

- 梦幻西游手游最早神兽获取途径是什么需要满足哪些条件
-
26-04-25
-

- 《Spider-Man/Superman #1》评测:漫威与DC最棒的一次联动
-
26-04-25