谷歌发布Gemini 3.1 Flash-Lite,主打“快与省”,性能碾压 2.5 Flash
时间:26-04-25
谷歌推出Gemini 3.1 Flash-Lite:专为高吞吐量场景设计的“快刀手”
3月4日,谷歌正式发布了Gemini 3系列的最新成员——Gemini 3.1 Flash-Lite。官方将其定位为该系列中速度最快、性价比最高的模型,并明确表示,这款新模型就是为开发者的大规模、高吞吐量工作负载量身定制的。在同等价位和模型级别中,它的表现堪称亮眼。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
从即日起,开发者可以通过Google AI Studio中的Gemini接口抢先体验预览版,而企业用户则可以通过Vertex AI平台获得服务。
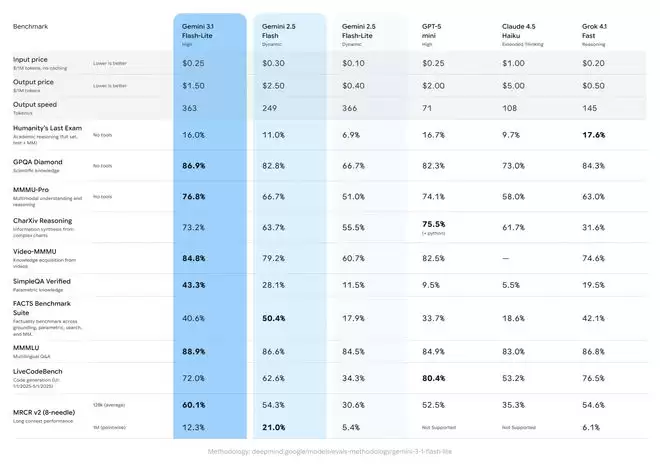
在定价方面,3.1 Flash-Lite的每百万输入Token成本为0.25美元,每百万输出Token则为1.50美元。那么,这个价格换来的是怎样的性能呢?根据Artificial Analysis的基准测试,3.1 Flash-Lite在保持同等甚至更高输出质量的前提下,其性能表现已经超越了前代的2.5 Flash。具体来看,它的首字响应速度提升了惊人的2.5倍,整体输出速度也增长了45%。这种低延迟特性,正是高频工作流不可或缺的基石,也让它成为开发者构建响应式实时体验的理想选择。
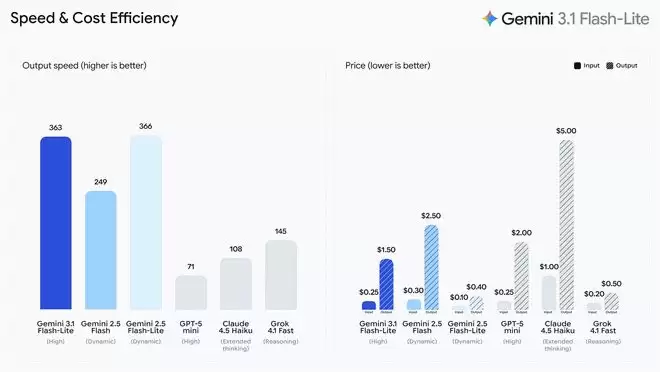
性能数据同样令人印象深刻。在Arena.ai排行榜上,3.1 Flash-Lite获得了1432分。更关键的是,在一系列推理和多模态理解的基准测试中,它都成功超越了同级别的其他竞争对手。例如,在GPQA Diamond测试中,它取得了86.9%的成绩;在MMMU Pro测试中,得分也达到了76.8%。这一表现,甚至让一些体量更大的前代模型都相形见绌。
除了原生的强悍性能,Gemini 3.1 Flash-Lite还有一个不容忽视的亮点:它在AI Studio和Vertex AI中,标准配置了“思考等级”功能。这意味着开发者可以根据具体任务的需求,灵活调节模型的“思考”深度。对于需要精细化管理的高频工作负载来说,这个功能简直是如虎添翼。因此,3.1 Flash-Lite的应用场景非常广泛:它既能游刃有余地处理对成本敏感的大批量任务,比如翻译和内容审核;也能胜任那些需要深度推理的复杂工作,例如生成用户界面、创建模拟环境,或是严格遵循一系列复杂指令。
市场已经给出了初步的反馈。目前,通过AI Studio和Vertex AI获得早期接入的开发者,以及拉提图德、卡特维尔和威灵等公司,已经开始利用3.1 Flash-Lite来解决大规模的复杂问题。这些早期测试者普遍强调了该模型在效率和推理能力上的优势。他们发现,这款模型能够以接近大体量模型的精准度来处理复杂输入,并且在遵循指令和保持输出一致性方面,表现得相当出色。
这就是谷歌发布Gemini 3.1 Flash-Lite,主打“快与省”,性能碾压 2.5 Flash的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- iPhone 16 Pro怎么拍夜景照片_iPhone 16 Pro夜间模式拍摄教程【技巧】
- iPhone 16耗电太快怎么办?这5个优化设置让续航提升一倍
- iPhone 16 Pro怎么设置双卡_iPhone 16 Pro双SIM eSIM设置方法【详解】
- 苹果手机怎么开启应用锁 iphone如何锁定屏幕上的App【攻略】
- 揭秘 Spatial 空间显示屏:三星如何让裸眼 3D 显示屏从概念变为现实
- AI 灯塔计划 ——2026 教育钉峰会(宜昌站)圆满举行
- 2026 高校宿舍必备平价好物清单|空气堡成热门首选,备考党闭眼冲
- 2026 游戏手柄手感评测:盖世小鸡这 3 款手柄刷新行业体验
- 男子利用电商“仅退款”规则恶意下单敲诈 900 余家网店:流水高达 1030 万元,获刑一年六个月
- 贝索斯 AI 底牌“普罗米修斯计划”曝光:从 OpenAI 挖走 xAI 联合创始人,拟建百亿资本巨兽








大家还在看
-

- 《无限暖暖》2.5版本「万灵的归途」前瞻直播情报汇总
-
26-04-26
-

- 《识质存在》谁还需要枪成就解锁指南
-
26-04-26
-

- 《识质存在》超爱红色区域成就解锁指南
-
26-04-26
-

- 《识质存在》墙什么墙成就解锁指南
-
26-04-26
