CVPR 2026 生成式 AI 观察梳理:视觉模型开始重写默认设定
视觉生成开始重写基础机制
过去几年,视觉生成与理解领域的技术演进,大体遵循着一条清晰的路径:一旦某种建模范式被证明行之有效,后续的研究浪潮便会蜂拥而至,围绕着这个既定框架,不断进行模型扩容、数据增强、采样优化或局部模块的微调,以此追求性能指标的持续攀升。
无论是扩散生成、视频世界模型,还是动作建模与视觉匹配,主流研究在很长一段时间里,更像是在为一座已建成的大厦进行内部装修和加固,而非重新审视其地基是否牢靠。
然而,从今年CVPR涌现的一批代表性工作来看,这种稳定的技术演进逻辑正在发生微妙而深刻的变化。越来越多的研究不再满足于在现有模型框架内进行“打补丁”式的性能改进,而是开始系统性地回溯那些在工程实践中被视为“理所当然”的基础设定。
扩散模型中的引导机制是否真的合理?视频生成是否必须建立在反复去噪的扩散过程之上?生成模型学习的预测目标,是否从一开始就遵循了最自然的数据分布?人体动作生成与语义匹配任务中,那些被粗粒度评价指标所掩盖的控制与泛化边界,是否也需要被重新划定?
这意味着,顶级学术会议上的竞争焦点正在悄然转移。相比于过去单纯比拼“在原有范式下把模型做得更强、分数刷得更高”,这批工作更值得玩味之处在于,它们开始同步触及决定模型行为方式的底层前提,并试图重新定义生成目标、控制逻辑、主干架构与表示方法。
简而言之,视觉AI的下一轮竞赛,正逐渐从性能的“军备竞赛”,转向对既有默认设定的“系统性重写”。
从静态引导到动态协同:重新审视扩散控制
这一趋势首先体现在一项关于扩散模型引导机制的工作上。由上海交通大学和vivo BlueImage Lab共同提出的《C²FG: Control Classifier-Free Guidance via Score Discrepancy Analysis》,直接挑战了条件扩散模型中一个近乎“默认”的组件——Classifier-Free Guidance(CFG)。
CFG通过调节条件分支与无条件分支之间的引导强度,来增强生成结果对输入条件的服从度,从而提升质量。但问题在于,扩散过程内部的噪声结构和分数差异并非一成不变,而是随着时间步动态演化的。使用一个固定的引导强度,很难在整个采样过程中都保持最优。
这项研究正是从这一被忽视的内部动力学出发,深入分析了不同时间步下条件分数与无条件分数之间的差异变化规律。结论指出,引导强度本质上不应是一个静态的超参数。基于此,研究者提出了C²FG方法,利用指数衰减控制函数,让引导强度在采样前期和后期自动动态分配:前期更强地利用条件约束保证语义对齐,后期则逐步减弱引导以避免过强控制导致的分布偏移和细节失真。
它打破的,是CFG长期依赖经验调参的惯性,将一个“手工设定的旋钮”重塑为一个与扩散动力学同步演化的智能控制变量。由于整个方法无需重新训练模型,可直接嵌入现有采样流程,其工程可迁移性也相当强。

挑战单一范式:视频生成的另一条路
当扩散模型内部的引导机制被重新理论化时,另一项工作则把问题推向了更底层的生成架构。苹果团队提出的《STARFlow-V: End-to-End Video Generative Modeling with Autoregressive Normalizing Flows》试图回答:高质量视频生成是否只有扩散模型这一条路?
当前,主流的高质量视频生成几乎清一色建立在扩散框架之上,反复去噪似乎成了唯一答案。归一化流(Normalizing Flow)虽然在图像生成中重获关注,却始终未在视频生成领域成为主流。
STARFlow-V并未简单地将图像流结构迁移到视频,而是针对视频生成长时序依赖和跨帧一致性的核心挑战,在时空潜在空间中重新构建了一套全局-局部的自回归流架构。全局潜在变量用于控制跨帧的因果依赖,减少长视频生成中误差逐帧累积的问题;局部潜在变量则保留帧内细节交互,确保空间纹理质量。
同时,通过引入流-分数匹配和视频感知的雅可比迭代,进一步提升了时间一致性和计算效率。这项工作并非在扩散框架内修修补补,而是直接挑战了“高质量视频生成必须依赖扩散去噪”的默认前提,建立起一种基于归一化流的端到端视频生成新范式。更重要的是,流模型天然的可逆结构和显式似然估计能力,使得同一个模型能够原生支持文生视频、图生视频、视频生视频等多种任务,无需为不同任务堆叠复杂分支。这不仅仅是一个替代架构,更像是在重新绘制视频生成的技术路线图。

回归本质:生成模型应该预测什么?
如果说前两项工作主要关注“生成过程如何被重新控制与实现”,那么MIT团队的工作《Back to Basics: Let Denoising Generative Models Denoise》则将审视的目光投向了扩散模型最核心的预测对象。
当前主流的去噪扩散模型,虽然名为“去噪”,但大多数实践并非直接预测干净图像,而是让模型去拟合噪声残差或带噪的中间状态。这一设定在工程上已沿用多年,却少有人追问:这是最合理的生成目标吗?
该研究指出,根据流形假设,自然图像分布位于相对低维且连续的数据流形上,而噪声空间则更加高维、分散且难以拟合。从这个角度看,让模型直接学习回归到干净数据本身,可能比在高维噪声空间中预测噪声分量更为自然和稳定。
基于这一认识,作者提出了JiT模型,不再依赖额外的标记器、复杂的预训练模块或辅助损失函数,而是直接使用大块(patch)Transformer在原始像素空间完成干净图像的预测。这个看似“回归朴素”的设计,其真正意义在于打破了“扩散模型默认预测噪声”的路径依赖,重新建立了一种以直接回归数据流形为核心的生成思路,也让基于Transformer的扩散模型在高分辨率自然图像上的建模逻辑变得更加自洽。

生成模型开始从「会生成」走向「会精确编排」
当视觉生成模型不断回溯底层机制进行重构时,另一条研究脉络则开始聚焦于“模型生成结果的可控性究竟能达到何种粒度”。
人体动作的“原子级”编排
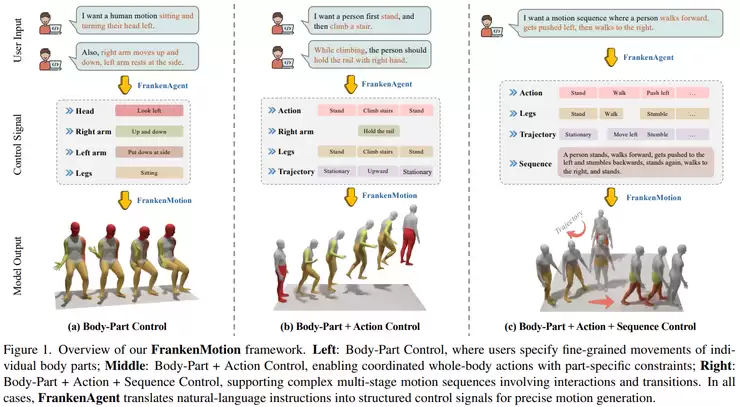
由德国图宾根大学、Tübingen AI Center及马克斯·普朗克信息学研究所共同提出的《FrankenMotion: Part-level Human Motion Generation and Composition》便是典型一例。
当前,文本驱动的人体动作生成已能根据“一个人走路”这样的整体描述生成相对自然的运动。然而,模型的控制粒度依然粗糙,它很难精确回答“左手何时抬起”、“下半身何时转向”或“动作切换发生在哪一帧”这类问题。
究其原因,一方面现有动作捕捉数据大多只有序列级标签,缺乏按时间对齐、按身体部位拆分的细粒度标注;另一方面,模型即使理解了整体语义,也难以同时兼顾局部肢体动作与全局时序一致性。
FrankenMotion将复杂的人体运动重新视为由多个“原子动作单元”组合而成,并让模型学习这些身体部位级动作之间的组合关系。研究首先通过自动化方法为现有动作序列生成逐帧、逐身体部位的层级文本标注,构建了新的数据集;进而训练模型同时接收序列级、动作级和身体部位级条件。这使得模型不仅知道“做什么动作”,更知道“身体的哪一部分在何时做”。
这意味着,人体动作生成正从“生成一个合理的动作片段”转向“按指令精确编排复杂的动作组合”,模型甚至能组合出训练集中从未直接出现过的细粒度复合动作。
语义对应的“泛化性”破局
与细粒度控制的需求相呼应,视觉理解中的匹配任务也在经历类似的范式转向。由意大利都灵理工大学、德国达姆施塔特工业大学、hessian.AI及ELIZA共同提出的《MARCO: Na vigating the Unseen Space of Semantic Correspondence》,关注的是语义对应任务中一个现实但常被基准测试掩盖的问题。
现有方法虽然在已标注的关键点上精度很高,但一旦查询点超出训练时见过的位置,或遇到未见过的物体类别,泛化能力便会急剧下降。这导致了基准测试成绩与实际可用性之间存在明显落差。
MARCO的核心突破在于,它不再满足于“在标注点上匹配得准”,而是试图让模型学会在未被标注的图像空间中也推断出合理的对应关系。研究在强大的视觉基础模型DINOv2之上,构建了一个更统一、轻量的对应框架,结合由粗到细的定位目标提升空间精度,并引入一种密集自蒸馏机制,将稀疏的关键点监督信号扩展为更致密的语义对齐信号。
这种设计带来的改变是根本性的:模型不再仅仅是记住训练时见过的对应点,而是开始学习物体表面更连续的结构关联。因此,在面对未见过的关键点或类别时,模型展现出了更强的泛化能力。实验表明,MARCO不仅在多个标准基准上取得了领先性能,在更严格的细粒度定位和未见关键点测试中提升尤为显著;同时,相比基于扩散的方法,其模型大小减少了约3倍,速度提升了约10倍。
这项工作的价值在于,它打破了语义对应领域长期存在的“高分数≠强泛化”的瓶颈,建立起一种更强调致密推断和未知空间泛化的新思路,推动语义对应从“点对点匹配”走向“在连续语义空间中寻找对应”。

将这几项工作放在一起审视,会发现它们虽然分属扩散控制、视频生成、人体动作生成和语义对应等不同方向,但其背后共享着一条清晰的研究脉络:视觉AI正在经历一场从“量变”到“质变”的思维转换。研究重心正从“沿着既定范式堆叠模型、调整参数、刷新榜单”,转向“重新审视并拆解那些被视为默认正确的底层设定,进而建立新的生成目标、控制机制与表示方法”。
有的工作在重新定义扩散模型应该如何被引导,有的在探索视频生成超越扩散模型的更多可能性,有的在追问生成模型究竟该预测什么,还有的在将模型的控制粒度与泛化能力从粗糙推向连续与真实。
可以说,当前最值得关注的已不仅仅是某个模型将指标提升了几个百分点,而是这批工作共同释放出的信号:视觉模型的下一轮竞争,其核心已从性能的增量竞赛,转向底层建模范式的重构竞赛。这场关于“基础假设”的再思考,或许将决定下一个技术周期的走向。
原创文章,未经授权禁止转载。详情见转载须知。
