2024理想汽车深度测评:高分辨率细节优化方案权威解析
在单目深度估计领域,提升输出分辨率是普遍趋势。当前许多方法能够生成2K乃至4K的深度图,表面上看,细节呈现更为丰富。
然而,在三维重建、新视角合成等对几何一致性要求严苛的实际任务中,高分辨率深度图的表现时常不及预期。物体边缘模糊、细小结构错位等问题频发,分辨率提升并未带来几何精度的同步飞跃。类似挑战在自动驾驶与机器人导航中同样关键——几何误差会干扰对障碍物边界的精准判断及可通行区域的可靠估计,最终影响规划与决策系统的稳定性。
问题的根源可能在于,主流方法仍遵循“固定分辨率预测,后置插值放大”的传统范式。这种做法虽能便捷地获得更大尺寸的图像,但对于细节区域而言,本质上是在放大既有的预测误差。对于依赖深度信息进行环境感知与建模的系统,此类误差不仅损害局部几何质量,更可能动摇整个感知决策链的可靠性。这促使业界进行反思:高分辨率深度估计的瓶颈,或许不在于模型复杂度,而在于深度信息本身的表示方式存在根本性局限。
基于这一洞察,浙江大学彭思达团队与理想研究团队合作,提出了名为《InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields》的研究。这项工作的核心并非在现有框架内追求指标提升,而是回归问题本质,重新探索在高分辨率条件下,如何更有效地对深度信息进行建模与利用。
为验证新范式的有效性,研究团队设计了一系列涵盖合成数据、真实数据及三维下游任务的系统性实验,旨在多维度、精细化地评估新方法在复杂几何与细节区域的实际性能。

论文地址:https://arxiv.org/pdf/2601.03252
突破分辨率限制的深度感知
研究团队通过覆盖合成数据、真实数据及下游三维任务的综合实验,系统验证了InfiniDepth在高分辨率深度估计、细粒度几何建模及大视角渲染方面的卓越性能。
首先,在团队专门构建的Synth4K数据集上进行了零样本相对深度评估。Synth4K包含五个来自不同高质量游戏场景的子集,每个子集提供数百张3840×2160分辨率的RGB图像及对应的高精度深度图,能够真实反映高分辨率下边缘、薄物体与复杂曲面的几何细节。

评估同时关注全图区域与高频细节区域,采用δ0.5、δ1和δ2作为核心指标。在全图范围内,InfiniDepth在五个子集上均取得最佳性能。例如在Synth4K-1上,其δ1达到89.0%,显著优于DepthAnything的83.8%和MoGe-2的84.2%;在Synth4K-3上,δ1进一步提升至93.9%,相比DepthPro、Marigold等方法优势明显;在Synth4K-5上,其δ1达到96.3%,在所有对比方法中位列第一。这些数据表明,该方法在高分辨率条件下具备稳定且一致的整体精度优势。

进一步聚焦于高频细节区域(通过多尺度拉普拉斯算子筛选出的几何变化剧烈区域)时,所有方法的性能均出现下降,但InfiniDepth的下降幅度最小,且在多数子集上保持领先。例如在Synth4K-1的高频区域,其δ1为67.5%,而DepthAnything和DepthAnythingV2分别仅为61.3%和60.6%;在Synth4K-3的高频区域,InfiniDepth的δ1为69.0%,相比MoGe-2的63.4%提升显著。整体而言,InfiniDepth在高频区域的δ1指标通常比主流方法高出约5到8个百分点,这证实了其在边缘、薄结构及局部几何突变区域拥有更强的细节表达能力。
需要指出的是,这类高频细节并非合成数据独有,在真实世界的复杂场景中同样普遍。例如在自动驾驶环境中,路缘、护栏、交通标志杆等关键元素往往具备细长、边界清晰且几何变化明显的特征,其深度估计的准确性直接关系到车辆对道路结构与可行驶空间的精确理解。因此,在这些区域保持稳健的几何表达能力,对于提升复杂道路环境下的感知可靠性具有直接的工程价值。
研究团队特别强调,这种性能差异并非源于后处理技巧。对于Synth4K的4K输出,大多数对比方法需先在较低分辨率下预测深度,再通过插值上采样至4K;而InfiniDepth得益于其连续的深度表示,可以直接在4K坐标位置预测深度值。因此,其在高分辨率评估中的优势反映的是模型原生的分辨率扩展能力。

在真实世界数据集(KITTI、ETH3D、NYUv2、ScanNet和DIODE)上的零样本相对深度评估中,InfiniDepth的表现与当前主流方法整体处于同一水准。例如在ETH3D上,其δ1达到99.1%,略高于MoGe-2的99.0%;在KITTI上,δ1为97.9%,与DepthPro、MoGe等方法基本持平;在NYUv2和ScanNet上,也未出现明显的性能退化。这些结果表明,即便模型仅使用合成数据训练,其连续深度表示并未损害对真实数据的泛化能力。这种对训练数据分布变化不敏感的特性,在自动驾驶和移动机器人等实际部署场景中至关重要,因为真实环境往往与训练条件存在显著差异,对感知系统的稳定性要求极高。

在尺度深度估计实验中,研究团队将InfiniDepth与稀疏深度提示机制结合,并在Synth4K及真实数据集上采用了更严格的δ0.01、δ0.02和δ0.04指标进行评估。在Synth4K的全图区域,InfiniDepth-Metric在Synth4K-1上的δ0.01达到78.0%,相比PromptDA的65.0%提升显著;在Synth4K-3上,其δ0.01达到83.8%,同样领先于所有对比方法。在高频细节区域,这一优势更为突出,例如在Synth4K-3的高频区域,InfiniDepth-Metric的δ0.01为37.2%,而PromptDA仅为24.7%,PriorDA和Omni-DC的表现更低。这表明,在细节区域和高精度尺度估计任务中,连续深度表示能够带来更显著的收益。

在真实数据集的尺度深度评估中,也观察到了一致的趋势。在KITTI和ETH3D上,InfiniDepth-Metric的δ0.01指标分别达到63.9%和96.7%,均优于现有方法;在DIODE数据集上,其δ0.01达到98.4%,在对比方法中排名第一。这说明该方法在引入稀疏深度约束后,能够在真实场景中实现高精度且稳定的尺度深度预测。

此外,在单视图新视角合成实验中,研究团队将InfiniDepth预测的深度用于构建三维点云并驱动高斯渲染。实验结果表明,相比采用像素对齐深度的方法,在大视角变化条件下,基于该方法构建的点云分布更加均匀,生成的新视角图像中几何空洞和断裂明显减少,整体结构更为完整。这证明连续深度表示能够为三维建模提供更加稳定和一致的几何基础。
这种更可靠的三维几何结构不仅有利于视觉重建与渲染任务,在自动驾驶和机器人系统中同样具有现实意义。更准确的空间几何信息有助于系统对周围环境形成更清晰的空间认知,从而为后续的导航规划与决策提供更加稳定的感知支撑。

深度表示的本质性重构
上述实验结果,源于研究团队围绕一个核心问题所设计的系统性实验:“深度表示方式本身,是否构成了分辨率扩展性与几何细节恢复能力的主要瓶颈?”
研究人员指出,现有单目深度估计方法普遍在固定的像素网格上进行预测,输出分辨率与训练分辨率强相关,高分辨率结果通常依赖插值或上采样,这不可避免地会损失高频几何信息。为验证问题是否源于表示方式,团队提出将深度建模为连续空间中的映射关系,使模型能够在任意图像坐标位置直接预测深度值。
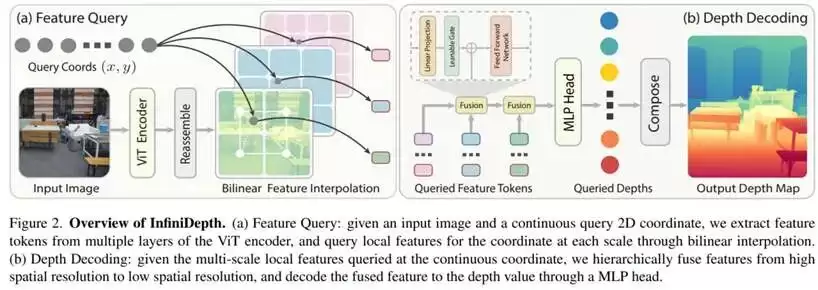
在数据设计上,为避免真实数据集中深度标注稀疏、分辨率有限和噪声较大的问题干扰实验结论,研究人员构建了Synth4K数据集,并进一步引入高频细节掩码,通过多尺度拉普拉斯能量筛选出几何变化最剧烈的区域,从而实现对模型细节恢复能力的定量评估。

在实验设置上,所有对比方法均使用相同分辨率的输入图像,并在评估阶段统一对齐尺度;对于4K输出,基线方法的结果通过上采样获得,而InfiniDepth直接在4K网格坐标位置进行深度预测,以确保对比实验聚焦于深度表示和解码方式的差异。在训练阶段,研究人员并未对整张深度图进行逐像素监督,而是随机采样大量坐标及其对应的深度值进行训练,这一策略既符合连续深度建模的设定,也使高分辨率监督更加灵活。

为验证各个模块的贡献,研究团队进一步设计了系统的消融实验。当移除连续深度表示、回退到传统的离散网格预测方式时,模型在Synth4K和真实数据集上的高精度指标普遍下降8到12个百分点;当去除多尺度局部特征查询与融合机制时,模型在细节区域的性能同样出现一致性退化。这些结果从定量角度证明,连续表示和多尺度局部查询是InfiniDepth性能提升的关键因素。

在新视角合成相关实验中,研究人员进一步分析了像素对齐深度在三维反投影过程中导致点云密度不均的问题,并基于连续深度表示所支持的几何分析能力,根据不同区域对应的表面覆盖情况分配采样密度,从而在三维空间中生成更加均匀的表面点分布。实验结果表明,这一策略在大视角变化条件下能够有效减少孔洞和几何断裂。

跨场景验证的稳健结论
综合上述实验可以看出,InfiniDepth的研究意义不仅体现在指标提升上,更在于研究团队通过多数据集、多指标和多任务的定量实验,清晰地论证了:高分辨率深度估计中几何细节恢复能力的主要瓶颈,确实来源于深度表示方式本身。在Synth4K这一高分辨率基准上,高频细节区域普遍达到5至10个百分点的性能提升,直接揭示了依赖插值的高分辨率预测在几何建模上的固有局限性。
同时,真实数据集上的零样本评估结果表明,连续深度表示并未削弱模型的泛化能力。而在引入稀疏深度约束后,其在高精度尺度深度估计中的优势进一步放大。结合新视角合成实验可以看到,这种表示方式不仅提升了二维深度图在细节上的一致性,也为三维点云构建和渲染提供了更加稳定的几何基础。
在此基础上,这类连续深度表示所带来的稳定几何结构,使得深度信息能够更自然地被用于后续的三维建模与环境理解。在自动驾驶和机器人系统中,这种高分辨率且一致的深度感知,有助于提升复杂场景下空间建模和导航决策的可靠性。
总体而言,研究团队通过在高分辨率合成数据、真实世界数据以及下游三维任务上的系统实验,用具体数据和指标证明了连续隐式深度表示在分辨率扩展性、几何细节恢复能力以及大视角渲染方面的综合优势,为单目深度估计的后续研究提供了清晰且可验证的方向。
研究团队与作者
本论文的通讯作者彭思达,现任浙江大学软件学院研究员。他于2023年在浙江大学计算机科学与技术学院获得博士学位,师从周晓巍教授和鲍虎军教授,本科毕业于浙江大学信息工程专业。
彭思达研究员在三维视觉、神经隐式表示以及深度感知等研究方向上具有扎实的研究积累和持续的学术贡献,已在多项国际顶级会议和期刊上发表高水平论文,并在多项学术评选中获得重要荣誉,包括2025 China3DV年度杰出青年学者奖和2024 CCF优秀博士论文奖。
此外,他在GitHub上分享的个人科研经验与学习资料获得了广泛关注。其研究兴趣从神经隐式深度估计进一步拓展至动态场景建模、空间智能体训练以及大规模三维重建等方向,强调解决具有实际应用价值且尚未充分解决的核心问题,推动新技术在真实行业场景中的落地与影响。

参考链接:https://pengsida.net/