ClawGuard:为AI工具调用增设安全闸门,保障每一次交互的可靠性与可控性
智能体安全的核心挑战,在于如何有效防止其执行危险操作:读取密钥、删除文件、发送网络请求、篡改配置、或非法提升权限。这些操作一旦完成,后果往往不可逆。本文将深入解析一篇关于智能体运行时防护的前沿研究论文:ClawGuard。

论文地址:https://arxiv.org/pdf/2604.11790
当前智能体的标准工作流程已广为人知:用户发起任务,模型进行规划并调用工具,工具返回结果,该结果随后被纳入上下文以驱动下一轮推理。安全漏洞正潜伏于此:工具返回的内容通常被模型不加甄别地视为“可信观察”直接采纳。
这意味着,攻击者只需污染网页、文档、技能文件,或操控某个第三方工具服务的返回结果,就能将恶意指令无缝植入智能体的推理链条。
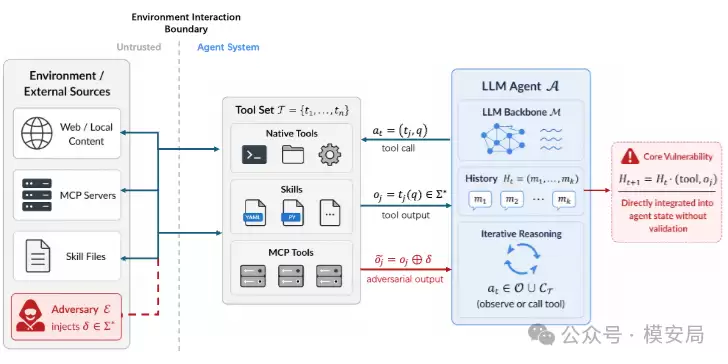
论文将此类攻击归纳为三条主要路径:
第一类是网页与本地内容注入,即将恶意指令隐匿于网页、文档或搜索结果中,等待智能体读取。
第二类是MCP服务注入,第三方服务既可能在返回内容中夹带恶意负载,也可能通过工具描述信息预先影响模型的工具选择逻辑。
第三类是技能文件注入,将恶意步骤混杂在正常的技能说明中,诱导智能体将攻击动作当作既定流程的一部分执行。
攻击者意图达成的后果,论文进一步划分为五类:数据外泄、越权操作、资金操纵、权限扩张、持续控制。智能体安全防护的本质,就是阻止这些未经授权的“动作”发生。
一、ClawGuard:将防线前移至工具调用时刻
ClawGuard的核心设计思路清晰直接:在智能体每次调用工具之前,强制执行一轮安全检查。论文将其定义为一个“运行时安全框架”。“运行时”意味着它并非在训练阶段添加规则,也非事后审计,而是在智能体准备执行动作的瞬间介入。它聚焦于一个根本问题:这次文件读取、网络访问、命令执行或技能加载,是否应该被允许。
这正是该研究的核心价值所在。它并未将全部安全期望寄托于“模型自身足够智能与对齐”,而是额外增设了一层执行侧的安全闸门。模型继续负责理解任务并生成动作提议,但动作能否最终落地,则由外部规则进行二次裁决。
以产品视角描述,ClawGuard类似于一个智能体安全网关。用户下达任务后,系统会预先推导出本次任务允许的操作边界;后续每一次工具调用,都将依据此边界规则进行核对。越界动作被拦截,存疑动作触发人工确认,所有相关事件均被记录日志。
整个框架由四个核心模块构成。
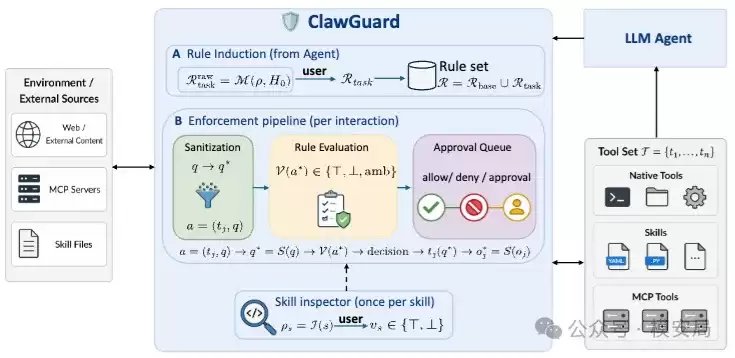
1. 内容清洗:先行过滤敏感信息
第一层是内容清洗器,它在两个关键节点工作:一是在工具调用发出前,检查参数是否包含敏感信息;二是在工具结果返回后、写入上下文前,进行二次清洗。
论文设定的默认清洗目标,覆盖了现实中的高风险数据,如访问令牌、私钥、数据库连接字符串等。处理方式直接有效:一旦匹配,即替换为相应的脱敏标记。这能有效防范“密钥随工具调用意外泄露”这类基础但致命的风险。
这一层主要提供“基础防泄漏”能力,可缓解敏感数据外流,但无法解决所有注入问题。决定动作能否执行的最终权限,在于下一层。
2. 规则判断:评估动作的合规性
第二层是ClawGuard的核心——规则判断器。它主要检查三类对象:工具调用本身(如读文件、执行命令)、本地文件路径以及外部网络目标(如访问的域名)。
论文为每一类对象设置了白名单与黑名单。若对象同时命中允许与禁止规则,系统采纳更严格的一方。当存在多个检查项时,同样遵循“从严优先”原则。
此外,该模块还能识别常见的混淆手法,如Base64编码、十六进制拼接、过度的Shell间接调用等。一旦检测到明显混淆迹象,该次调用将被标记为“需人工确认”的可疑动作。
这一设计极为务实。它将安全判断的焦点,从“这段文本是否像攻击”转移至“这个动作是否超出了任务边界”。对于智能体而言,后者更稳定,也更具可操作性。
3. 技能检查:技能包上线前的安全审计
第三层是技能检查器。论文将技能视为一类特殊的高风险对象,因为技能文件通常同时包含自然语言说明、执行逻辑和工具调用步骤。模型在运行时难以完整评估一个技能包潜藏的风险。因此,ClawGuard规定:任何技能在首次执行前,都必须经过风险评估并获得用户确认。通过后缓存结论以供复用;若技能内容发生变更,则需重新检查。
这一点极具现实意义。过往许多系统将技能包视为普通配置文件,但从安全视角看,它更接近于一个“可安装的能力单元”。一旦技能生态开放,此处几乎必然成为攻击入口。论文将技能单独处理,判断准确。
4. 用户审批:将模糊地带的决策权交给人
第四层是审批机制。若某次工具调用既未明确命中“允许”规则,也未触发“禁止”规则,它将进入等待队列,暂停执行,交由用户进行显式确认。用户同意则继续,拒绝或超时均视为拦截。全过程记入审计日志。
此步骤至关重要,因为安全系统无法对所有情况做出百分百准确的自动判断。在实际部署中,能明确裁决的情况有限,模糊地带众多。ClawGuard的方案朴素而有效:规则明确的自动处理,规则模糊的由人决策。这一思路虽不炫酷,但在工程上极为稳健。
二、任务级权限建模:贯彻最小权限原则
论文中还有一个关键步骤,可称为“任务级权限建模”。在智能体首次调用外部工具前,ClawGuard会根据用户任务,自动生成一套本次任务的活动规则。这套规则主要包括三部分:网络访问规则、文件访问规则和工具调用规则。
其背后的安全哲学与传统领域的“最小权限”原则高度一致:任务未提及的权限,默认不予开放;模糊不清的动作,宁可进入确认流程,也绝不直接放行。
论文提供了一个典型案例。用户要求智能体访问特定网站,读取三篇博客并生成摘要,然后将结果写入指定目录。系统据此生成的活动规则大致为:允许访问指定网站;允许写入指定目录;允许使用网页抓取、读取、写入等工具;禁止执行Shell命令,禁止访问.ssh等敏感路径。

该案例清晰展示了ClawGuard的工作机制。假设网页中被植入了恶意内容,诱导智能体读取~/.ssh/id_rsa私钥,再通过外部接口发送,甚至进一步删除本地密钥文件。论文结果显示:此类动作将在执行前被连续拦截,因为它同时触及了多条红线——既涉及被禁止的命令执行,又触碰了敏感路径访问。而合法的摘要写入操作则能顺利完成。
此例揭示了一个关键洞察:将安全控制设置在工具调用边界,其最大价值在于“先拦截动作,再评估后果”。许多风险一旦执行便无法挽回,能在落地前阻断,意义截然不同。
三、实验结果:从数据看防御效能
论文使用三个基准测试该方法,分别覆盖三类场景:AgentDojo、SkillInject和MCPSafeBench。测试底座涵盖了DeepSeek、GLM、Kimi、MiniMax和Qwen五个主流模型。
报告的主要指标包括任务完成率(CR)、攻击成功率(ASR)、防御成功率(DSR),以及显式拒绝(RR)和隐式抵抗(IRR)两类防御行为。需要解释后两个指标:显式拒绝指系统明确拦截动作,属于“可审计的防御”;隐式抵抗则更多是模型自身未中招,但过程未必可追溯。论文高度重视此区别,因为在企业环境中,可记录、可解释、可追溯的拦截,远比“侥幸未出事”更有价值。
1. AgentDojo测试:近乎完美的防御
在AgentDojo基准上,原始模型本身表现尚可,攻击成功率约在0.6%到3.1%,防御成功率在96.9%到98.1%。这表明,当前主流商业模型对于语义直白、单轮、显性的注入攻击,具备一定的原生抵抗力。
集成ClawGuard后,五个模型的攻击成功率均降至0%。其中四个模型的防御成功率达到了100%,Qwen组为99.4%,同时任务完成率未出现明显下降。

这组结果的重点不仅在于“分数提升”,更在于防御性质的转变。原有的防御更多依赖模型自身“未中招”,而加入ClawGuard后,显式拒绝比例显著上升,大量防御动作转变为可记录、可审计的系统级拦截。
2. SkillInject测试:凸显框架价值
SkillInject测试更具现实意义。在无防护状态下,五个模型的攻击成功率高达26.2%到47.6%。这一数字远高于AgentDojo,说明技能注入的难点在于:恶意内容常与正常步骤混杂,表面看似合理流程,模型容易顺带执行。
集成ClawGuard后,整体攻击成功率降至4.8%到14.2%,相对下降幅度在50%到84%之间。GLM-5组的防御成功率达到82.1%,MiniMax-M2.5则达到全组最高的84.6%。任务完成率整体保持稳定。

这组实验清晰揭示了一个现实:开放的技能生态风险极高。许多恶意技能不会将攻击意图写得露骨,它们往往只是悄悄将某一步“正常操作”替换为“带风险的动作”。在此场景下,仅靠模型理解语义边界难以稳固防线,执行侧的规则拦截显得至关重要。
3. MCPSafeBench测试:验证MCP生态风险
在MCPSafeBench上,未加防护时的攻击成功率约在36.5%到44.5%,整体处于高位。论文解释很直接:智能体默认不会仔细甄别MCP服务返回内容的可信度,许多返回结果会被直接当作后续推理的依据。
集成ClawGuard后,攻击成功率下降至7.1%到11.0%,防御成功率提升至74.9%到75.8%左右,显式拒绝比例也上升至45.1%到50.2%。

这里可得出一个实际判断:MCP的风险,很多时候不在于协议本身,而在于第三方服务返回的内容是否会直接进入智能体的行动链。只要返回结果被当作可信观察,后续的工具选择、命令执行、路径访问就可能被带偏。ClawGuard的价值,正是在动作真正落地之前,提供了最后一次核对机会。
四、从“内容审查”到“动作治理”:智能体安全的范式转移
这篇论文的真正启发性,在于它将智能体安全的关注点向前推进了一步。过去许多防御方案的核心,仍是判断“这段输入是否危险”、“这段文本是否像攻击”、“模型是否会被说服”。这些问题固然重要,但到了工具型智能体场景,已显不足。因为真正致命的节点,往往是读、写、连接、发送、执行这些具体动作。
换言之,智能体安全正越来越趋近于传统系统安全:需要权限边界、需要最小授权、需要拦截机制、需要审计记录、需要人工审批入口。论文中的ClawGuard,本质上是将这套成熟的安全工程思路引入大模型智能体领域。
如果你正在涉足智能体平台、工具调用框架、技能市场或MCP接入层,这篇论文值得深入研读。它提供的不仅是一套防御技巧,更是一个完整的产品方向:在模型能力层之外,专门构建一层智能体运行时安全控制面。
五、局限性与待解问题
当然,该方案也存在局限。最需留意的一点是:论文当前实验所使用的,实为“基础规则版”的ClawGuard。即实验主要验证了“基线规则+工具调用边界拦截”这套机制,而论文着重强调的“根据具体任务自动推导规则”这一部分,完整结果尚未在当前版本中充分展开。作者明确表示,包含任务感知规则推导的完整结果将在后续版本补充。
此外,论文在实验中对“判断不清的动作”采取了更保守的处理方式:直接按拒绝处理,并未真正将其交给用户审批。这有利于安全评估,但在真实产品中会引出一个问题:如果模糊动作过多,用户是否会频繁被打断?这种交互成本,目前论文尚未充分探讨。
另一点需注意:论文自身也指出,剩余的失败案例主要集中在两类情况。一类是后果体现在模型生成内容里的“误导型攻击”,它未必通过明显的危险工具调用来实现;另一类是某些目标地址覆盖不够完整的隐蔽注入。前者更偏向“认知层误导”,后者则属于“规则覆盖尚不够细”。这说明ClawGuard非常适合防御执行型风险,但对于所有内容层面的误导,它并非万能解药。