英特尔展示纹理集神经压缩技术 纹理大小最多可缩小18倍
对于PC玩家而言,硬件升级的循环似乎永无止境:追求更逼真的视觉效果与更沉浸的游戏体验,往往意味着必须投资更昂贵的显卡与显存。然而,是否存在一种方案,能够在不牺牲画质的前提下,显著降低游戏对显存与存储空间的需求?
纹理压缩技术,特别是基于人工智能的新一代方案,正成为破解这一困境的核心。它不仅能让游戏体积大幅“瘦身”,更能让那些显存有限的旧款或入门级显卡流畅运行新作。目前,英伟达与英特尔均已公布了各自的神经纹理压缩技术路线图,旨在为数以亿计的新老硬件带来性能与兼容性的双重提升。这无疑是应对显存与内存瓶颈的一条关键技术路径。
技术对决:英特尔TSNC与英伟达NTC
近期,两大图形技术巨头相继公布了其神经纹理压缩的详细进展。英特尔正式发布了纹理集神经压缩SDK,而英伟达则在GTC 2026大会上,深入解析了其依托硬件加速的神经纹理压缩技术。

英特尔研发的纹理集神经压缩技术与英伟达的神经纹理压缩技术,其战略目标高度一致:极致优化纹理资源,从而大幅缓解显存与存储空间的压力。英伟达此前曾披露,其NTC技术可在游戏中实现高达85%的显存占用降低,同时保持视觉保真度无损。

TSNC技术的工作原理与压缩效能
英特尔通过一段技术演示视频,直观展现了TSNC的压缩能力。该技术能够将纹理资产压缩至原始大小的1/18,其视觉质量与行业标准压缩方案相比,差异控制在难以察觉的范围内。
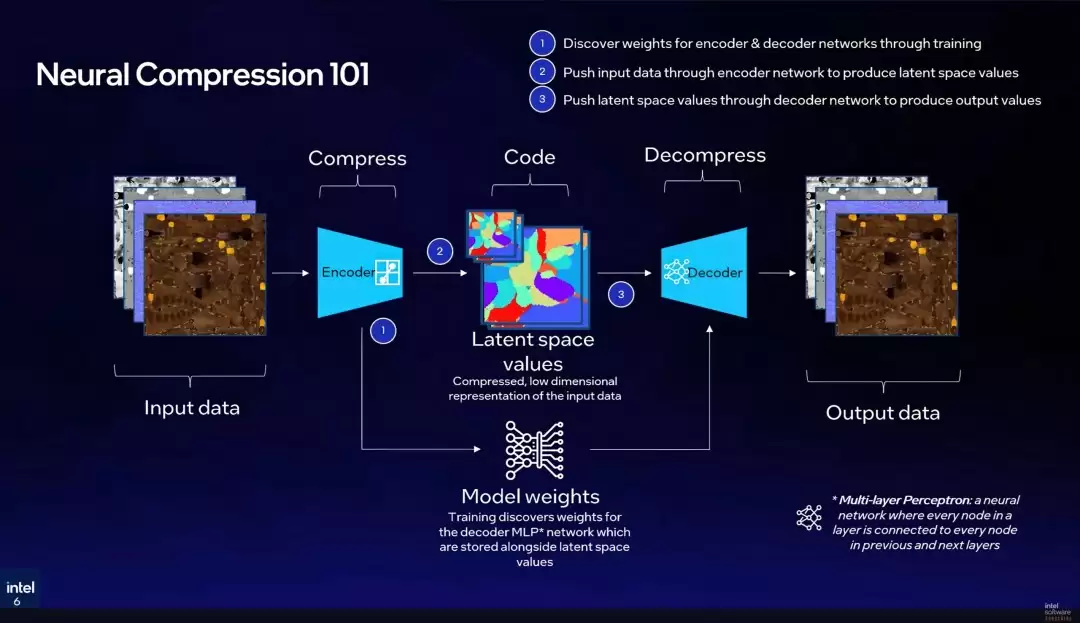
其核心技术流程,是运用经过训练的神经网络来处理标准的BCN格式纹理。整个过程分为三个核心阶段:首先,原始纹理数据通过专用的AI编码器模型进行高比率压缩;随后,压缩后的数据以优化后的空间值格式进行编码存储;最后,在渲染时由对应的网络解码器实时解压。最终结果是纹理数据流显著减小,即使在最高压缩比下,画质损失也极为有限。
当然,TSNC模型的效能依赖于前期使用海量标准化纹理数据集进行的充分训练,以构建出能够替代传统压缩管线的AI模型。这一技术带来的直接优势包括:更小的游戏包体、更快的纹理加载速度、更低的显存占用,并借助现代GPU的AI加速单元,实现整体渲染效率的提升。
应用策略:在效率与画质间取得平衡
TSNC技术提供了灵活的应用模式,开发者可以根据项目需求,在节省存储空间、降低显存负载或提升渲染帧率等不同目标之间进行权衡。
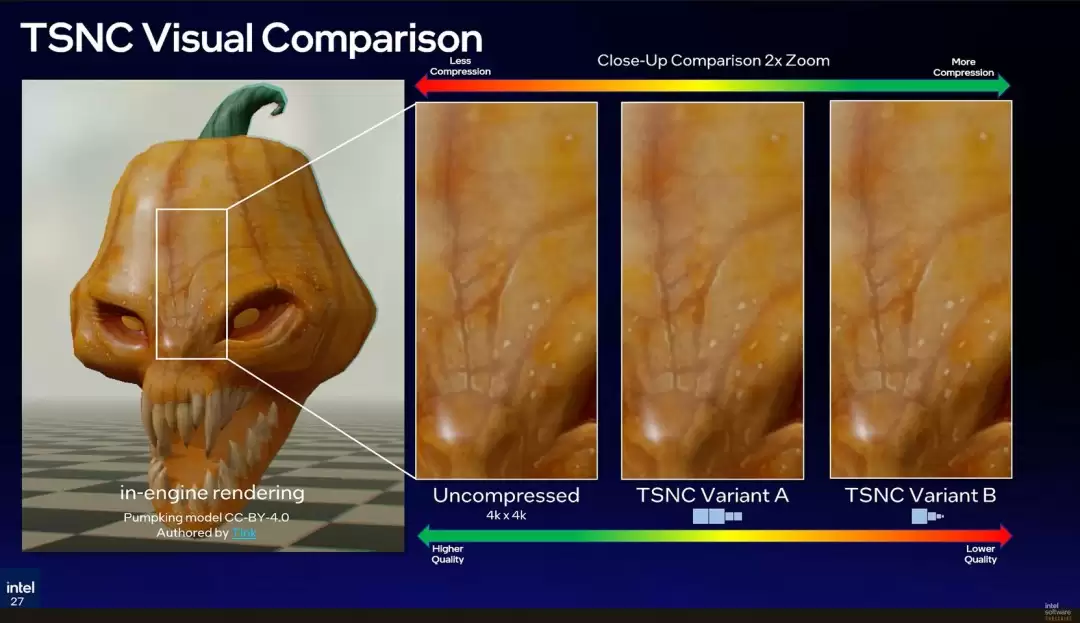
英特尔主要提供了两种预设方案。第一种称为“变体A”,它能够实现最高9倍的纹理压缩率,同时将视觉质量损失降至极低水平,几乎无法被肉眼感知。
当项目追求极致的性能与资源节省,需要达到18倍的压缩比时,则需要启用“变体B”。该模式能带来更显著的性能增益,但作为交换,视觉效果会出现可量化的轻微下降。
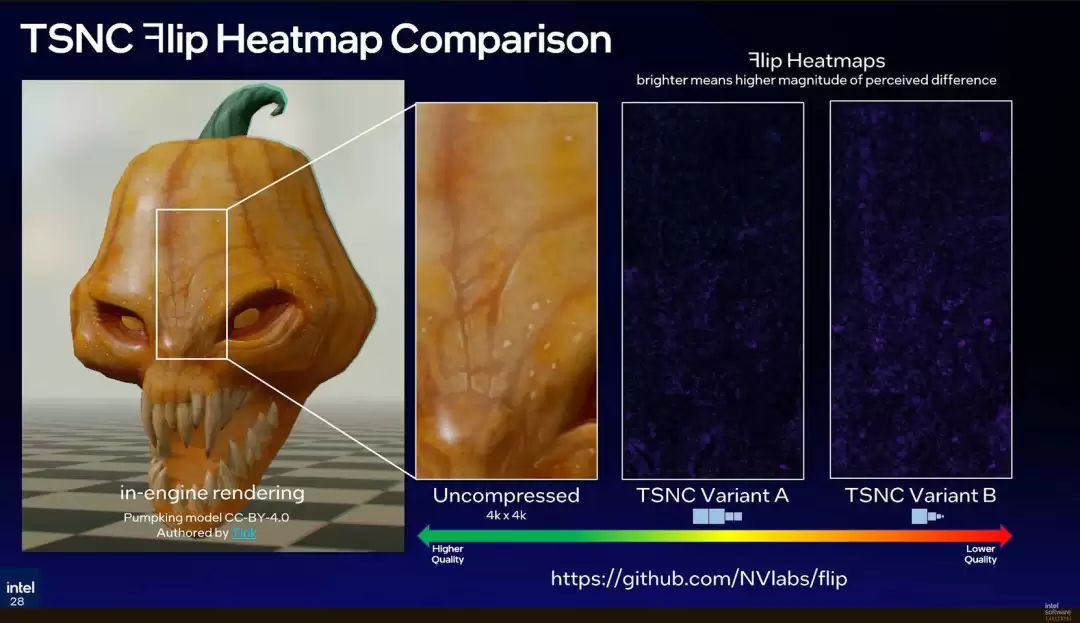
英特尔采用英伟达的FLIP图像质量评估工具来精确测量画质损失。数据显示,“变体A”导致的平均视觉差异约为5%,而“变体B”的差异则上升至7%,为开发者提供了明确的数据参考。
性能基准测试与开发者路线图
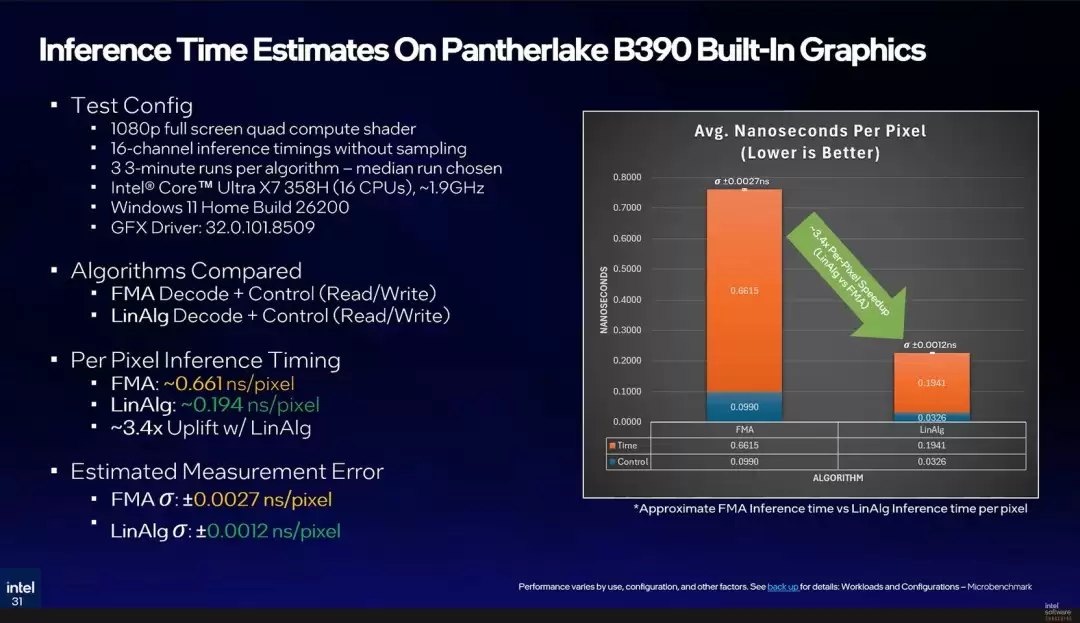
最后,英特尔在搭载Arc B390集成显卡的酷睿Ultra Series 3处理器平台上对TSNC技术进行了性能基准测试。该平台集成的XMX AI加速引擎,能够为神经纹理的解码计算提供硬件级支持。
测试结果展现了出色的效率:AI模型生成首个纹理像素的耗时仅为约0.194纳秒。这一速度足以确保纹理解压过程不会引入可感知的渲染延迟或卡顿。根据计划,该技术将于今年晚些时候以Alpha测试版向开发者提供,后续将发布Beta版及最终稳定版,具体发布日期有待进一步公布。