AI驱动从头设计多样化小分子结合蛋白,韩国团队发现能选择性识别压力激素的蛋白质
从通用骨架到定制传感器:AI如何从头设计小分子结合蛋白
在合成生物学与生命科学领域,创造能够高亲和力、高特异性结合小分子的蛋白质,是实现精准生物传感与可控分子开关的核心技术瓶颈。传统路径主要依赖对天然蛋白的筛选改造,或基于有限已知骨架进行物理建模,其通用性与规模化设计能力始终受限。
这一局面正迎来变革。韩国科学技术院(KAIST)生物科学系的研究团队取得关键突破。他们运用深度学习驱动的蛋白质结构生成与序列设计技术,选定NTF2样折叠作为“通用骨架”,从头设计出多样化的、可特异性结合小分子的蛋白质。更重要的是,团队成功将这些设计蛋白转化为类似化学诱导二聚化(CID)的功能性生物传感器。其中,一款能选择性识别压力激素皮质醇的传感器,展示了从设计到应用的完整闭环。这项研究不仅推进了蛋白质从头设计的方法论,更提供了解决小分子识别难题的可测量技术方案。
相关研究以《Small-molecule binding and sensing with a designed protein family》为题,发表于《自然·通讯》。
研究亮点:
* 利用人工智能从头设计识别特定化合物的蛋白质,并将其应用于功能性生物传感器。
* 传统方法主要涉及寻找天然蛋白质或修改其功能,而本研究则通过AI设计“定制”了具有所需功能的蛋白质。
* 研究成果在疾病诊断、新药研发和环境监测等领域展现出广泛的应用潜力。

论文地址:https://www.nature.com/articles/s41467-026-70953-8
数据集:构建NTF2通用骨架库
实现定制化设计的首要前提,是建立一个多样化的蛋白质骨架资源库。研究团队以NTF2样折叠为核心,通过多阶段流程构建了这一基础库。
首先,采用家族级“幻觉”方法,生成了首批1,615个NTF2骨架结构。随后,利用ProteinMPNN工具为这些骨架重新设计氨基酸序列,并通过AlphaFold进行结构预测与筛选,确保其能稳定折叠成预设构象,从而获得包含3,230个骨架的第二集合。为进一步扩增多样性,团队使用Rosetta软件参数化生成更多骨架,同样经过序列设计与AlphaFold验证,最终得到包含6,838个骨架的第三集合。完整构建流程如下图所示:

NTF2骨架生成流程示意图
经过层层筛选,团队获得了大量可用于实验验证的蛋白质编码序列。这些序列涵盖了对皮质醇(HCY)、华法林(WRF)、罗库溴铵(ROC)、阿哌沙班(APX)、伊立替康活性代谢物SN-38(IRI)以及17-α-羟基孕酮(OHP)等多种小分子具有潜在结合能力的候选蛋白。
设计具有多样化口袋几何结构的NTF2蛋白家族
为何选择NTF2折叠?该折叠由3条α螺旋和一张弯曲的6股β折叠片构成,其天然形成的内部结合口袋大且构象灵活,为容纳不同形状与化学性质的小分子提供了理想的结构框架,其结构如下图所示:

NTF2折叠的可设计结构框架
自然界中NTF2家族的多样性主要源于其不规则的环区与独特的四级结构,这些因素共同塑造了口袋形状与功能。本研究旨在设计一个口袋几何结构高度多样化、同时尽量减少复杂环区的NTF2蛋白家族,以保持其模块化与易于设计的特性。整体设计流程见下图:

基于NTF2折叠的小分子结合蛋白设计流程示意图
在获得超过一万个具有不同口袋形状的NTF2设计蛋白后,研究进入关键环节:赋予其小分子识别能力。团队使用RIFdock分子对接方法,将六种在化学性质与结构上各异的小分子——包括皮质醇、华法林、罗库溴铵、阿哌沙班、SN-38和17-α-羟基孕酮——分别对接到这些骨架的中心口袋中。
核心挑战在于精准构建蛋白质与小分子间的极性相互作用(如氢键)。这需要在口袋内部引入正确的极性氨基酸残基,同时维持蛋白质整体的结构稳定性。为此,团队采用了两种互补策略:
方法一(RIFdock to HBNets):将前五种小分子对接到第一批骨架库中,强制要求至少存在一个由预计算氢键网络(HBNet)介导的相互作用,随后使用基于天然序列信息的Rosetta设计进行优化。
方法二(无限制RIFdock):将后三种小分子对接到第二、三批骨架库中,不预设氢键约束,随后使用专门在蛋白质-小分子复合物数据上训练的LigandMPNN进行序列设计,该工具能在设计时显式考虑配体存在。
筛选环节同样严谨。研究人员计算了蛋白质-配体间的氢键数量、结合自由能变化和接触表面积。对于第二种方法的设计,还结合了单序列AlphaFold的预测结果,筛选出既能准确折叠又能形成预期结合位点的设计(评估指标见下图)。
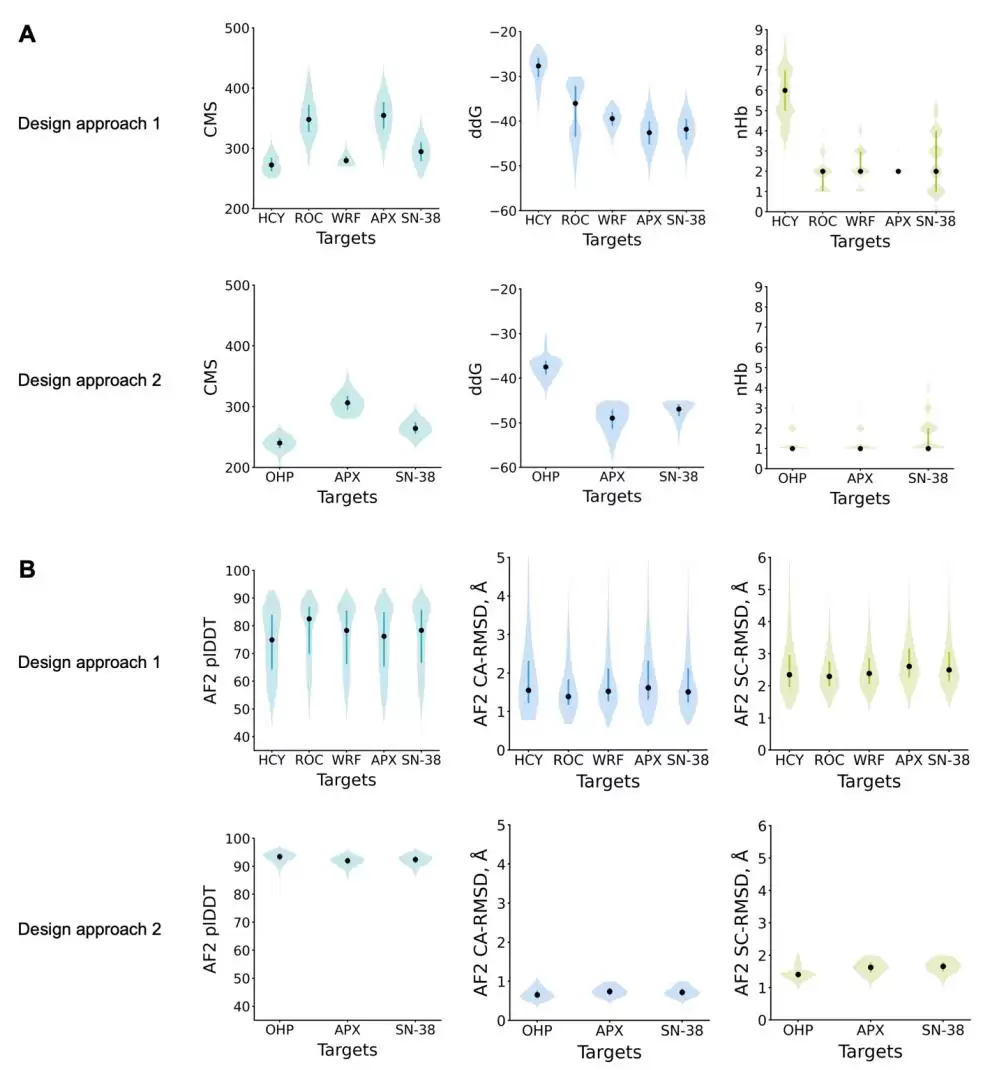
设计蛋白的评估指标
成果展示:基于NTF2的小分子结合蛋白可应用于生物传感器
理论设计能否经得起实验检验?研究团队通过一系列严谨的实验,验证了该设计策略的有效性,并展示了其向功能性生物传感器转化的潜力。
设计结合蛋白的结构表征
结构解析提供了最直接的证据。团队解析了两个蛋白质-配体复合物的晶体结构:结合皮质醇的hcy129和结合阿哌沙班的apx1049。
其中,hcy129与皮质醇复合物的分辨率高达1.5 Å。结构比对显示,其整体折叠与计算机设计模型高度一致,关键氢键残基和配体构象也完美匹配(下图A,B)。这证实了预构建氢键网络策略的成功,实现了极性相互作用的精准“雕刻”。

设计的皮质醇与阿哌沙班结合蛋白的结构分析
另一方面,apx1049与阿哌沙班复合物的结构(分辨率2.1 Å)与设计模型吻合度更高,关键相互作用,包括氢键和芳香环之间的π-π堆积作用,几乎被完全复现(下图C,D)。这些结果在原子尺度上证实了该设计策略能够高精度地构建蛋白质-配体结合界面。

设计的皮质醇与阿哌沙班结合蛋白的结构分析
设计结合蛋白的特异性评估
结合能力之外,特异性至关重要。研究人员系统测试了六种设计蛋白对六种不同配体的结合情况,并以常见的非特异性结合蛋白——白蛋白作为对照。
结果显示,hcy129.1、iri807.1和apx1049等高亲和力蛋白对各自的靶标分子表现出良好的特异性。而白蛋白对大多数测试配体几乎没有结合。这初步验证了设计策略在实现特异性识别方面的有效性。
当然,挑战依然存在。例如,对于疏水性很强的华法林,设计蛋白wrf1071的结合亲和力与白蛋白相近,这表明在区分此类分子时,非特异性结合仍是一个需要攻克的难题。总体而言,该方法已能实现较高水平的特异性识别,但在区分结构相似分子和优化对强疏水配体的选择性方面,仍有提升空间。
生物传感器构建:皮质醇诱导异源二聚体的设计与表征
设计的终极目标是实现应用。以皮质醇为例,其在生理样本中浓度很低,但当血浆浓度超过38 nM时,可能提示库欣综合征等疾病。为了将高特异性的hcy129用于生物传感,需要进一步提升其结合亲和力。
研究团队通过单点饱和突变筛选出有益突变,并构建组合突变体文库进行酵母展示筛选,成功获得了亲和力显著提升的变体(见下图)。

皮质醇结合蛋白hcy129的亲和力优化过程
最佳变体hcy129.1的解离常数(KD)达到68 nM,比原始设计提高了31倍(下图C)。结构分析表明,亲和力的增强主要源于与皮质醇之间更强的疏水相互作用(下图D)。
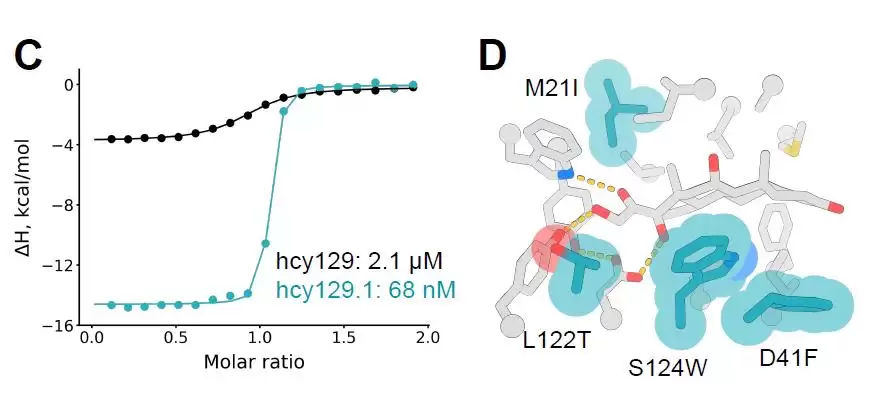
用于皮质醇感知的化学诱导异源二聚体设计与表征
接下来,便是构建传感器的关键一步。团队对hcy129.1进行改造,并设计了一个与之匹配的小型蛋白miniH11。二者只有在皮质醇存在时,才会像“分子胶水”一样稳定地结合在一起,形成三元复合物。
最后,将该体系与NanoBiT荧光素酶报告系统融合。实验表明,该传感器仅在皮质醇存在时才会产生强烈的发光信号,其半最大效应浓度(EC50)约为72 nM(下图H),与测得的结合亲和力一致,且在没有皮质醇时背景信号很低。这成功验证了将设计蛋白转化为功能性生物传感器的可行性。

皮质醇依赖的发光响应曲线
至此,这项研究完整演示了从AI设计通用骨架,到定制小分子结合蛋白,再到构建实际可用的生物传感器的全流程。
结语
这项研究为小分子结合蛋白的从头设计开辟了一条新路径。它跳出了依赖发现或改造天然蛋白的传统范式,转向“按需定制”。通过人工智能模型在原子层面精确规划蛋白质-配体相互作用,并经过严格的实验验证,标志着蛋白质理性设计能力的一次重要跃迁。
其意义不仅在于技术本身,更在于显著拓展了应用边界。从疾病早期诊断中对痕量生物标志物的精准检测,到新药研发中针对特定靶点的分子识别,再到环境监测中对污染物的实时感知,具备高度特异性和可编程性的定制化生物传感器,正成为连接前沿生命科学与现实世界需求的坚实桥梁。随着技术体系的不断成熟,这座桥梁将承载更多前所未有的应用驶向未来。
参考文献:https://www.nature.com/articles/s41467-026-70953-8https://phys.org/news/2026-04-ai-proteins-built-specific-compounds.html