「先筛选后智能标注」范式兴起 重构计算机视觉开发链路
先筛选,后标注:计算机视觉落地降本增效的新范式
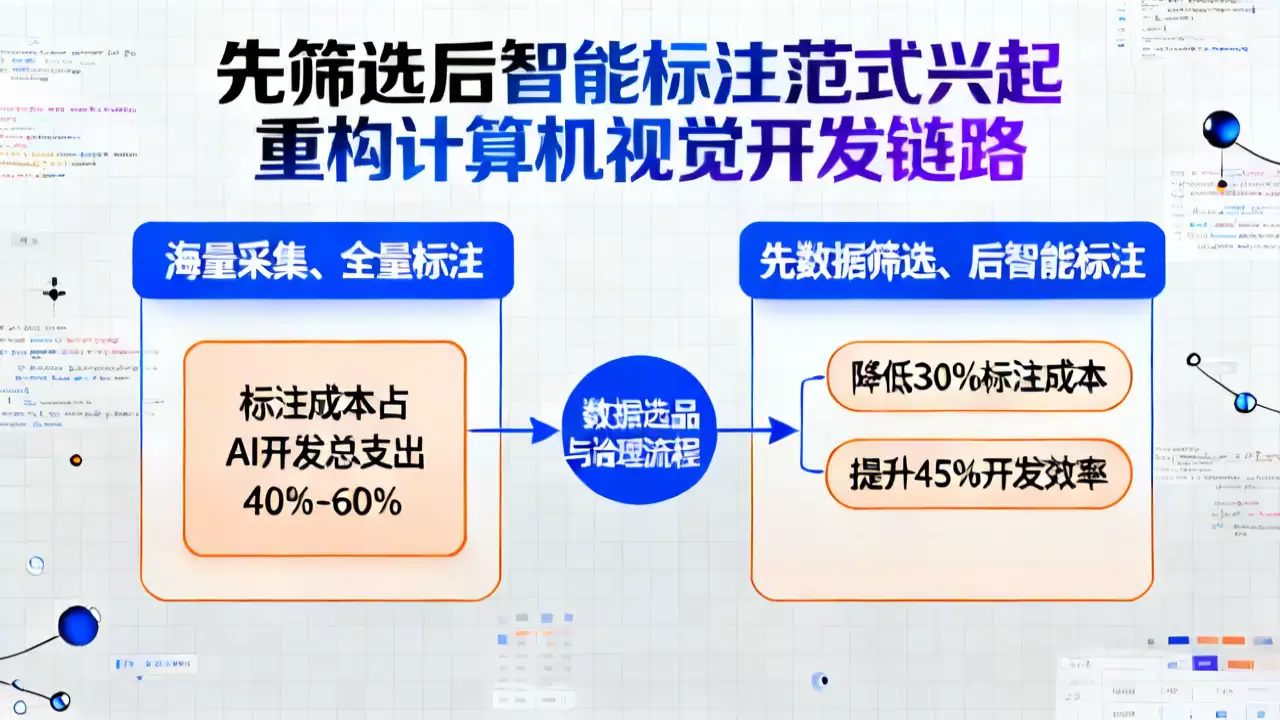
InfoWorld最近的一篇报道点明了一个新趋势。在计算机视觉领域,一种“先数据筛选、后智能标注”的开发范式正在悄然兴起,并迅速获得行业关注。数据可不会说谎——采用这种模式的团队,标注成本平均能降低30%以上,模型开发效率的提升更是普遍超过45%。这显然已不再是一个实验性想法,而是一条经得起验证的降本增效核心路径。
数据“粗放时代”的痛点
长久以来,计算机视觉模型性能的天花板,几乎是由标注数据的质量直接决定的。过去行业的通行做法,是典型的“海量采集、全量标注”粗放逻辑。结果呢?光是标注这一个环节,就吃掉了整个AI开发总预算的40%到60%。更令人头疼的是,大量的时间和金钱被投入到重复、低价值数据的标注上,这些投入非但没有换来模型效果的线性增长,反而因为引入了过多噪声数据,拖慢了整个迭代步伐。许多垂类场景的落地项目,最终都卡在了“数据成本过高”这道规模化关卡上,难以推进。
规模化落地催生新需求
随着自动驾驶、工业质检、智慧安防这些硬核场景进入大规模应用深水区,数据标注环节的供需矛盾变得尤为尖锐。一方面,垂类场景的要求极其定制化、精细化,公开的通用数据集根本满足不了,企业只能自己动手,采集和标注场景专属数据。另一方面,专业的标注成本居高不下——单张工业场景图片的标注费用可能高达数十元,而人工标注的错误率还普遍徘徊在15%以上,这些错误样本一旦进入训练流程,对模型的影响反而是负面的。这不只是小公司的困扰,连特斯拉的AI团队也曾公开表示,那些低价值的重复标注数据,对模型提升的贡献几乎为零,只会无谓地消耗资源。
范式转换:从“先标注”到“先筛选”
那么,破局点在哪里?答案就在于流程的重构。新兴的“先筛选后智能标注”范式,核心就是彻底碘伏了旧有的工作流。它不再是上来就标注,而是首先对采集到的原始数据做一轮“精加工”:去重、清除模糊样本、进行多样性校准。这一步的目标很明确,就是优先筛选出对模型效果提升贡献最大的那20%核心数据,让它们进入标注队列。
接下来,大模型驱动的智能标注工具会接手,完成大部分数据的半自动标注工作。人类专家只需要集中精力,对最后那些棘手、边缘的特殊样本进行校验和修正。根据InfoWorld的行业调研,采用这套流程的科技企业,标注环节的人工投入平均锐减了62%,而标注数据的准确率却逆势攀升至98%以上。最直观的效果是,模型迭代周期从以前的平均3个月,大幅缩短到了1个月左右。
未来竞争:从“标注产能”到“数据治理能力”
随着智能标注工具本身越来越成熟,行业的竞争焦点正在发生根本性转移。未来的比拼,将不再是简单的“标注产能”或人力规模,而是转向更前置、也更核心的“数据治理能力”。具体来说,就是企业针对特定垂类场景,进行高价值数据筛选、清洗和全生命周期管理的能力。这将成为下一阶段计算机视觉公司真正的核心竞争力。
值得注意的是,这一高效范式的价值并不仅限于计算机视觉。它已经开始向更宏大的多模态大模型训练的数据处理环节渗透。业内分析普遍预期,类似的精细化数据治理方法,有望将大模型训练所需数据集的采购与处理成本,再降低至少四分之一,从而为人工智能的更广泛、更普惠化落地,再添一把火。