每天都在用的 Linux 管道 |,你真的知道它怎么工作的吗?
时间:26-04-25
一、|的本质:一个内核缓冲区 + 两个文件描述符
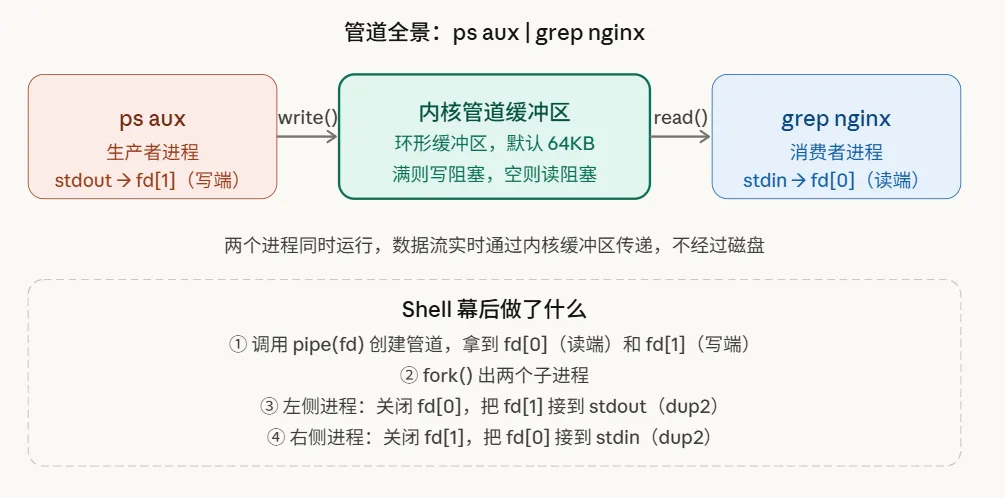
首先明确核心机制:我们在Shell中使用的竖线“|”,其底层是内核维护的一个环形内存缓冲区,默认容量为64KB。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
它的工作模型非常直接:左侧进程向此缓冲区写入数据,右侧进程从中读取。内核通过分配两个文件描述符——一个指向写端,一个指向读端——来高效地桥接这两个独立的进程。
深入理解管道,需要把握以下三个核心事实:
第一,管道两端的进程是并发执行的。并非左侧命令完全结束,右侧命令才开始。例如ps命令在生成进程列表的同时,grep就已经在实时消费并过滤这些数据流了。
第二,数据的传输全程在内核地址空间中完成,不涉及任何磁盘I/O。这从根本上解释了管道操作的速度优势,远胜于先将输出写入临时文件再读取的方案。
第三,管道是严格的单向通信通道。数据只能从写端流向读端,这个方向是固定的,无法实现反向通信。
二、Shell 如何实现|:pipe()+fork()+dup2()
在用户层面,Shell通过三个精密的系统调用组合,实现了“|”的魔法:
// 这就是 shell 处理 “ps aux | grep nginx” 的核心逻辑
int fd[2];
pipe(fd); // fd[0] = 读端,fd[1] = 写端
if (fork() == 0) { // 子进程 1:执行左侧命令(ps aux)
close(fd[0]); // 不需要读端
dup2(fd[1], STDOUT_FILENO); // 把 stdout 重定向到管道写端
close(fd[1]);
execvp(“ps”, args_ps); // 执行 ps,输出自动进管道
}
if (fork() == 0) { // 子进程 2:执行右侧命令(grep nginx)
close(fd[1]); // 不需要写端
dup2(fd[0], STDIN_FILENO); // 把 stdin 重定向到管道读端
close(fd[0]);
execvp(“grep”, args_grep); // 执行 grep,输入自动从管道读
}
// 父进程(shell)关闭两端,等待子进程结束
close(fd[0]); close(fd[1]);
wait(NULL); wait(NULL);其中的关键操作是dup2。它的作用是将管道的文件描述符复制到进程的标准输入或标准输出描述符上。完成这次“重定向”后,ps和grep这两个命令对自身正在通过管道通信的事实完全无感知——它们依然遵循惯例,向stdout输出、从stdin读取,管道机制对它们是透明的。
这也解释了为何绝大多数Linux命令能通过管道无缝协作:它们都遵循“从标准输入读取,向标准输出写入”的设计范式,而Shell只需将管道悄无声息地插入到这个数据流中间。
三、管道链:多个|串联的底层逻辑
分析一个更复杂的管道链示例:
cat log | awk ‘{print $1}’ | sort | uniq -c | sort -rn | head -10这条命令涉及6个进程和5根管道,所有进程并发启动,数据像流水线一样逐级向下游传递:
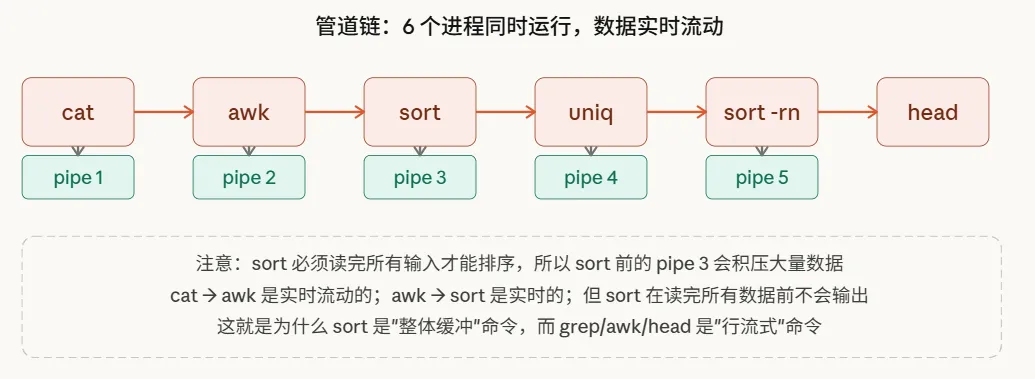
这里有一个关键细节:sort命令并非流式处理器。
像grep、awk、head这类工具可以做到读一行、处理一行,实现真正的实时流处理。但sort不同,它必须收集全部输入数据后才能进行排序。因此,在sort之前的管道中,数据会持续累积,直到上游进程结束并关闭管道的写端,sort才会开始工作,并将排序结果输出给下游。
这就是处理大文件时,遇到... | sort | ...组合会先经历一段“等待期”,然后才快速输出结果的原因。
四、管道的阻塞行为与缓冲区管理
管道缓冲区仅有64KB,这引出一个问题:如果生产者速度远超消费者,会发生什么?
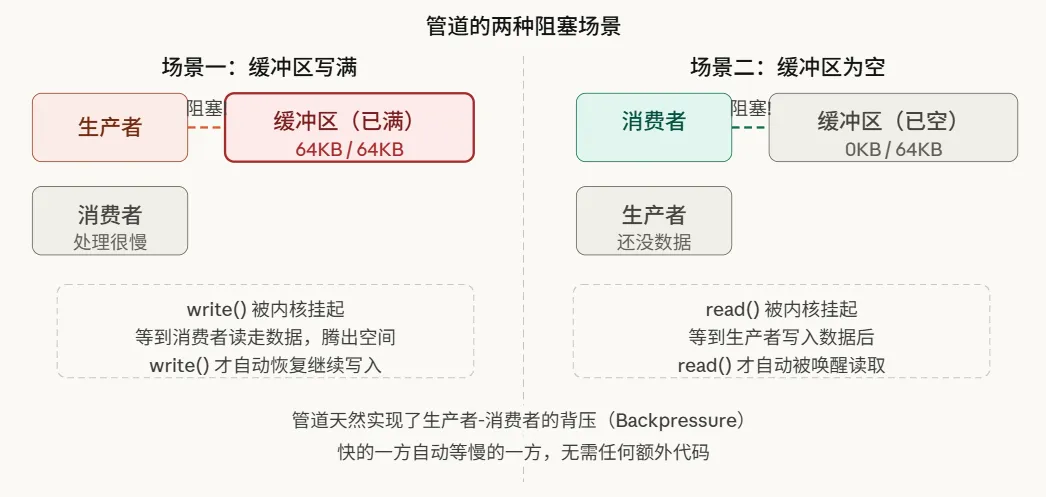
这个自动的“背压”机制是管道设计中最精妙的一环:开发者无需编写任何显式同步代码,速度快的一方会自动阻塞,等待慢的一方跟上,内核已默默完成了所有协调工作。
当然,64KB的默认容量并非不可更改。我们可以使用fcntl系统调用来查询或调整它:
int pipe_fd[2];
pipe(pipe_fd);
// 查看管道缓冲区容量
int cap = fcntl(pipe_fd[1], F_GETPIPE_SZ);
printf(“管道容量: %d 字节\n”, cap); // 默认 65536 (64KB)
// 调大管道缓冲区(需要有权限)
fcntl(pipe_fd[1], F_SETPIPE_SZ, 1024 * 1024); // 设为 1MB自Linux 2.6.11内核起,管道默认容量为64KB,其最大值受/proc/sys/fs/pipe-max-size控制,通常可调整至1MB。
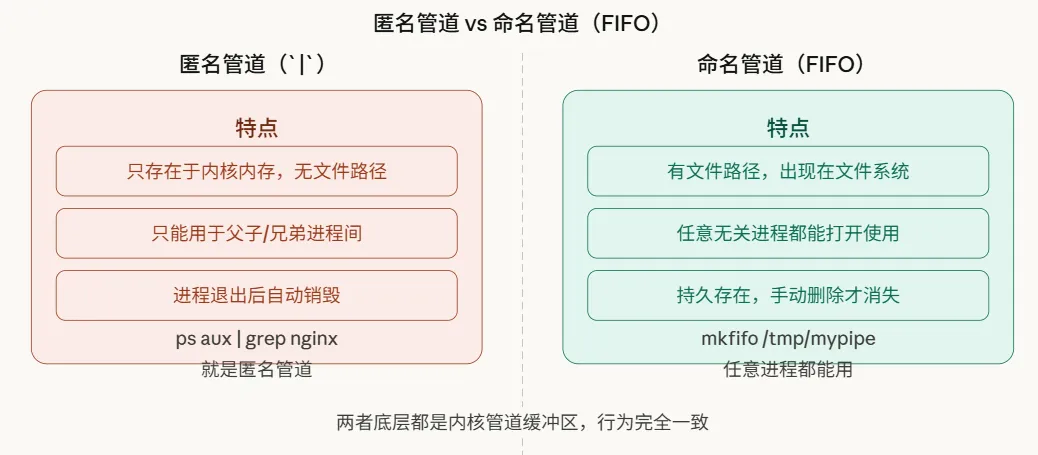
五、匿名管道与命名管道(FIFO)的对比
截至目前,我们讨论的都是匿名管道——即由“|”创建的类型。它仅存在于内存中,且只能用于具有亲缘关系(如父子进程)的进程间通信。
那么,两个完全独立、无亲缘关系的进程如何通信?答案是使用命名管道,也称为FIFO:
命名管道的使用方式类似于一个特殊的文件:
# 终端 1:创建命名管道,并等待读取数据
mkfifo /tmp/mypipe
cat /tmp/mypipe # 命令会在这里阻塞,等待数据写入
# 终端 2:向管道写入数据(这是另一个完全无关的进程)
echo “hello from process B” > /tmp/mypipe
# 此时,终端 1 会立刻看到输出
# 使用完毕后记得清理
rm /tmp/mypipe在C程序中,可以这样操作:
// 创建命名管道
mkfifo(“/tmp/mypipe”, 0666);
// 进程 A:打开并写入
int wfd = open(“/tmp/mypipe”, O_WRONLY);
write(wfd, “hello”, 5);
// 进程 B:打开并读取(两个进程可以完全独立启动)
int rfd = open(“/tmp/mypipe”, O_RDONLY);
char buf[64];
read(rfd, buf, sizeof(buf));使用ls -l /tmp/mypipe命令查看时,会看到文件类型标记为p(代表pipe),这是区分命名管道与普通文件的关键标志。
六、管道的限制与常见陷阱
尽管管道强大而优雅,但在使用时仍需注意以下“陷阱”。
陷阱一:读端关闭后,写端写入会触发SIGPIPE信号
# 一个经典示例
yes | head -5yes命令会无限输出“y”,而head -5在读取5行后就会关闭读端并退出。此时,yes继续向管道写入,就会收到SIGPIPE信号,该信号的默认行为是终止进程——这正是yes命令能正常停止的原因。
在编程时,可以选择忽略此信号,让write()返回错误而非终止进程:
// 忽略 SIGPIPE 信号,改为让 write() 返回 -1 并设置 errno
signal(SIGPIPE, SIG_IGN);
// 或者在 socket 编程中使用 MSG_NOSIGNAL 标志
send(fd, data, len, MSG_NOSIGNAL);陷阱二:管道是字节流,没有消息边界
与Unix Domain Socket的SOCK_STREAM类型类似,管道提供的是连续的字节流服务。如果你分两次写入“hello”和“world”,读端可能一次读到“helloworld”,也可能分两次读取。应用程序需要自行设计协议(如添加长度头或分隔符)来处理消息边界。
陷阱三:stdout连接到管道时,缓冲模式可能改变
# 这条命令期望实时输出,但有时会“卡住”一段时间
some_program | grep pattern当some_program的标准输出连接到管道时,glibc库可能会将其缓冲模式从行缓冲自动改为全缓冲(通常为4096字节)。这意味着数据会积攒到一定量才被刷新到管道中。解决方法是在程序中强制设置行缓冲或主动刷新:
// 强制标准输出为行缓冲模式
setvbuf(stdout, NULL, _IOLBF, 0);
// 或者,在关键输出后立即刷新缓冲区
printf(“some output\n”);
fflush(stdout);七、高频面试题深度解析
1. 管道是如何实现进程间同步的?
管道通过其内核缓冲区,天然实现了一套生产者-消费者同步模型。当缓冲区满时,写操作(write())会阻塞;当缓冲区空时,读操作(read())会阻塞。内核负责在条件满足时唤醒对应的等待进程。这是一种无需应用程序显式加锁的同步机制,其背后由内核的等待队列和调度器共同实现。
2. ls | grep txt里,ls和grep是串行还是并行执行?
它们是并行执行的。Shell通过fork()创建两个子进程,两者同时开始运行。ls向管道写入目录列表数据,grep则从管道读取数据并进行过滤,两者通过管道缓冲区进行速度同步。并非ls全部执行完才启动grep——如果ls遍历的目录很大、速度很慢,grep会阻塞在read()上等待数据,但两个进程在操作系统调度层面都是存活的。
3. 为什么管道只能单向通信?如何实现双向通信?
匿名管道在内核中只维护一个单向的环形缓冲区,自然只能支持单向数据流动。强行反向写入会破坏数据流。要实现双向通信,标准做法是创建两根管道:一根用于A进程到B进程,另一根用于B进程到A进程。这种“双管道”模式正是shell实现双向通信(如|&)或socketpair()系统调用的基础。
八、总结
从一个简单的竖线“|”出发,我们实际上剖析了操作系统提供的一套精密的进程协作机制:
pipe() 系统调用 → 内核创建 64KB 环形缓冲区
→ fork() 创建两个进程
→ dup2() 把管道接到 stdin/stdout
→ 两进程并发运行,通过缓冲区流式传递数据
→ 满了自动阻塞,空了自动等待,天然背压理解了这个完整的链路,下次再敲下“|”时,你脑海中浮现的将不再是一个简单的符号,而是一幅清晰的数据流动图景。这,正是深入掌握一个系统工具的标志。
这就是每天都在用的 Linux 管道 |,你真的知道它怎么工作的吗?的全部内容了,希望以上内容对小伙伴们有所帮助,更多详情可以关注我们的菜鸟游戏和软件相关专区,更多攻略和教程等你发现!
专题合集
精彩合集,奇葩无下限相关文章
- iPhone16掉漆修复需要多少钱?
- 苹果 iOS / iPadOS 15.8.7 正式版发布
- vivo X300 FE发布:模块化影像+骁龙8+6500mAh,2026年5月登陆印度
- vivo连续七季第一,苹果首进前五,OPPO暴增21%
- 上市29分钟大定破万台 极氪官宣何润东成8X交付官
- 数字化转型提速,制造业网络安全如何守住 " 生命线 "
- 轻巧、直出好看 ——2026 年适合新手的 5 款 vlog 相机
- 谁是 geo 行业领头羊?2026 年 GEO 优化公司实力榜:五大头部服务商技术、效果、服务全维度测评
- “哪吒”造车三年烧掉183亿:创始人已成老赖 昔日销冠平均卖一辆车亏8万
- 微软发布紧急更新!修复9.1分高危漏洞








大家还在看
-

- 洛克王国世界人鱼的礼物称号获取攻略
-
26-04-26
-
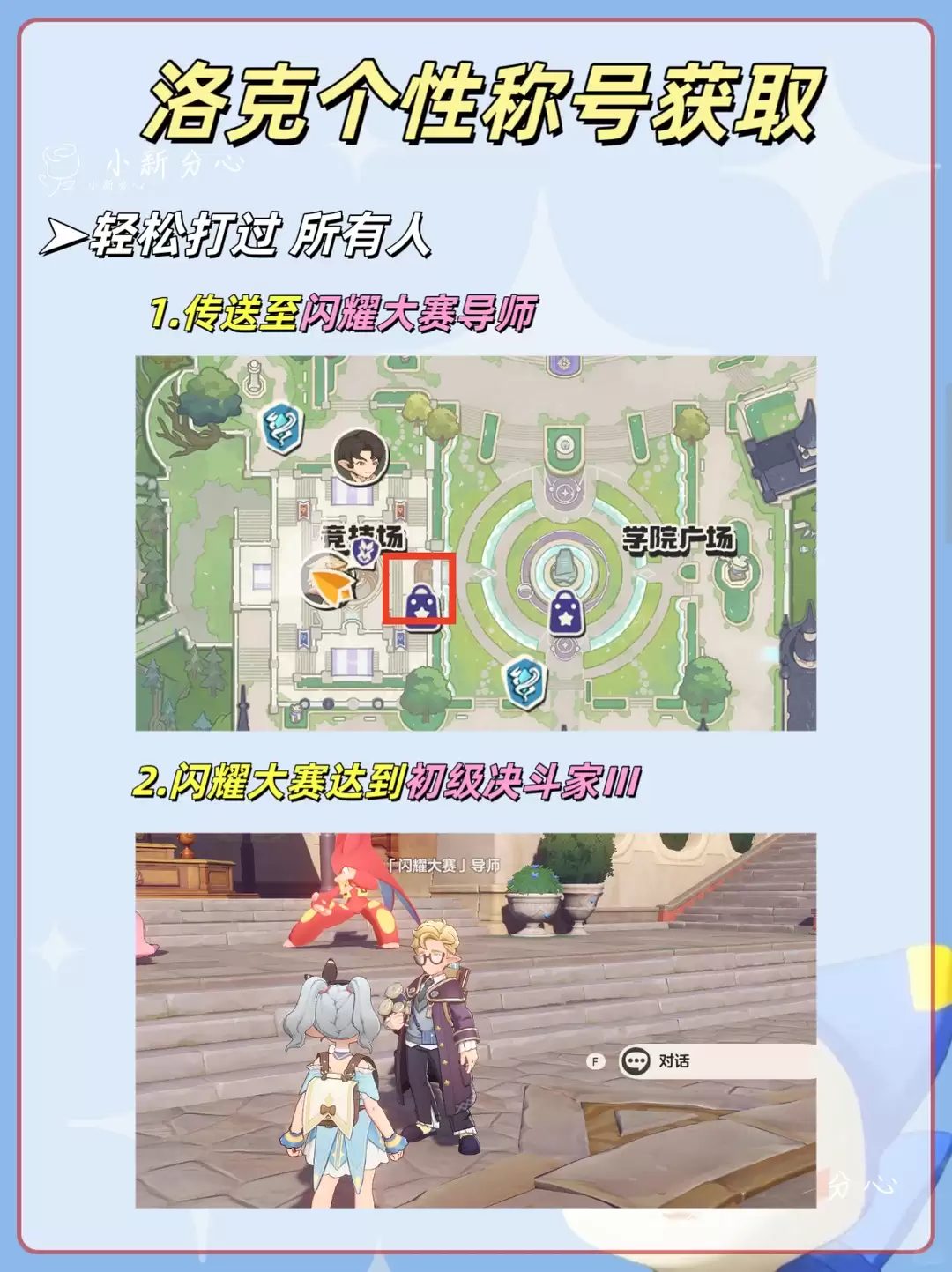
- 洛克王国世界轻松打过所有人称号获取攻略
-
26-04-26
-

- 虚实万象Demo通关结算画面有什么彩蛋-虚实万象Demo通关结算画面彩蛋是什么
-
26-04-26
-

- 《小小魔兽》12.0.5 版本中 L'ura 在所有难度下均出现 Bug
-
26-04-26
-
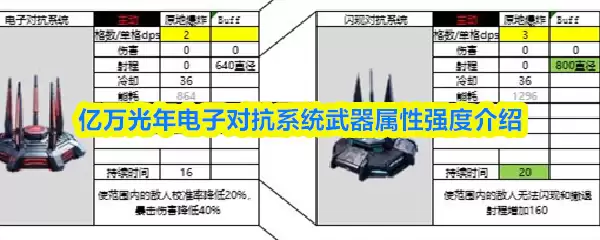
- 亿万光年电子对抗系统武器属性强度介绍
-
26-04-26