大模型那么火,教你一键玩转开源Llama3大模型
大模型那么火,教你一键玩转开源Llama3大模型

Meta的Llama 3正式登场了。这次,Meta一口气推出了8B和70B两种参数规模的预训练及指令微调模型。最引人注目的是,这些模型即将登陆AWS、Google Cloud、Microsoft Azure等主流云平台,并且获得了AMD、Intel等硬件巨头的鼎力支持,生态布局可谓全面铺开。
Llama3官方链接直达:https://llama.meta.com/llama3
接下来,我们从几个核心维度,带大家深入了解一下Llama3的究竟,并掌握上手使用它的方法:
1、Llama3介绍、表现及技术剖析
2、如何体验和下载Llama3模型
3、Llama3的调用方式
4、和行业专家一起聊聊Llama3
1.Llama3介绍
“迄今为止最好的开源大模型”
全新的Llama 3,无论是8B还是70B版本,都被视为对Llama 2的一次重大飞跃。它在多项基准测试中表现卓越,被广泛认为是当前开源模型中的新标杆。经过精细的指令微调后,模型在实用性上也有了显著提升:错误拒绝率降低了,回答的一致性更高了,生成的响应也变得更加丰富多样。
Llama3模型详细信息一览

性能表现
Llama 3的进步是全方位的,尤其在推理、代码生成和遵循复杂指令方面,能力大幅增强,这让模型变得更加“听话”和好用。可以说,它在性能和用户体验上都迈上了一个新台阶。
具体来看,Llama 3 8B参数模型在至少9项关键基准测试中,表现均优于同量级的其他开源模型,比如Mistral 7B和Google的Gemma 7B。它领先的测试领域包括:
MMLU:多任务语言理解基准测试。
ARC:复杂阅读理解测试。
DROP:数字化阅读理解测试。
GPQA:涵盖生物、物理和化学的专家级问题集。
HumanEval:代码生成测试。
GSM-8K:数学应用题。
MATH:数学基准测试。
AGIEval:问题解决测试集。
BIG-Bench Hard:常识推理评估。
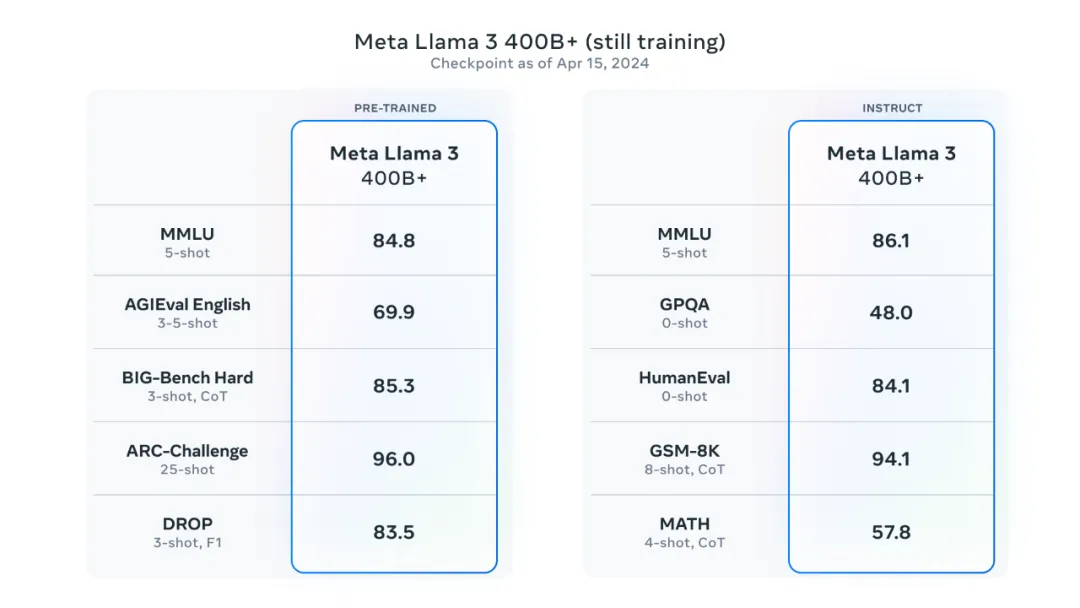
而更大的Llama 3 70B模型实力更为强悍,它在MMLU、GPQA、HumanEval、GSM-8K和MATH这五项基准测试中,甚至超越了Anthropic的Claude 3 Sonnet。这个成绩足以说明,Llama 3 70B在广泛的应用场景中都具备顶级的竞争力。

Meta团队在开发时不仅盯着基准测试分数,更关注模型在实际运用中的表现。为此,他们专门构建了一个全新的高质量人工评估集,包含1,800个提示词,覆盖了12种关键应用场景:比如寻求建议、头脑风暴、分类、编程、创意写作、信息提取和逻辑推理等。
下图展示的就是基于这个评估集,Llama 3 70B与Claude Sonnet、Mistral Medium以及GPT-3.5进行的人工对比测评结果。

还有一个令人印象深刻的对比:Llama3-8B模型在部分测试中的表现,甚至超越了上一代的Llama2-70B模型。这直观地体现了架构和数据带来的代际飞跃。

技术详情
Llama 3的成功并非偶然,它源于在模型架构、训练数据、规模扩展和指令微调这四个核心环节上的系统性创新与优化。
模型架构
Llama 3采用了经典的仅解码器Transformer架构,并在Llama 2的基础上做了关键升级。一个显著变化是词汇表扩大到了128K token,这大大提升了语言编码的效率,对最终性能增益贡献不小。此外,在8B和70B模型中,Llama 3均引入了分组查询注意力(GQA)机制,有效提升了长序列推理时的效率。模型在8,192个token的序列上进行训练,并通过掩码确保注意力不跨越文档边界。
训练数据
数据是模型的基石。Llama 3的预训练数据量超过了15万亿token,全部来自公开来源。这是什么概念?其规模是Llama 2数据集的七倍之多,其中包含的代码数据更是翻了两番。为了打造更通用的能力,数据集中有超过5%是高质量的非英语数据,覆盖超过30种语言。
当然,量变还需质变。为了确保数据质量,团队开发了一套复杂的数据过滤管道,包括启发式规则、NSFW过滤器、语义去重以及文本质量预测模型,层层筛选用以训练的核心语料。
扩大预训练规模
如何高效地利用海量数据是关键。团队通过深入研究缩放定律,精准优化了数据配比和训练计划。结果显示,在消耗了15万亿token进行训练后,8B和70B模型的性能依然保持着对数线性的提升趋势,意味着还有持续进步的潜力。
在工程实现上,通过综合运用数据并行、模型并行和管道并行三种并行化策略,团队在两个定制的24K GPU集群上高效完成了训练。这一系列优化使得Llama 3的整体训练效率相比Llama 2提升了约三倍。
指令微调
为了让预训练模型更好地胜任对话任务,团队融合使用了监督微调(SFT)、拒绝采样、近端策略优化(PPO)和直接策略优化(DPO)等多种技术。行业经验表明,SFT中使用的提示质量,以及PPO/DPO中使用的偏好排序数据,对最终模型的对齐效果影响巨大。通过对这些数据进行极其细致的筛选和质量控制,Llama 3在推理和编码任务上取得了显著突破。
算力消耗与碳排放
训练如此规模的模型,资源消耗是绕不开的话题。Llama 3预训练使用了功耗为700W的H100-80GB GPU,累计消耗了约770万GPU小时。据此计算,训练过程产生的碳排放量约为2290吨二氧化碳当量。Meta表示,这部分碳排已通过其可持续发展计划予以全额抵消。

2.Llama3模型体验和下载

想第一时间体验Llama 3?目前有几个便捷的途径:
Hugging Face在线体验:
https://huggingface.co/chat/
Meta官方AI聊天:
https://www.meta.ai/
模型下载申请:
需要下载模型到本地部署的开发者,可以访问Meta官方页面申请:
https://llama.meta.com/llama-downloads
对于国内用户,建议可以先在Hugging Face上尝试。此外,Llama中文社区的官网 https://llama.family 也正在积极部署,即将提供更便捷的国内体验链接和模型下载服务。
3.Llama3的调用方式
要上手调用Llama 3,首先得了解它设定的几个特殊标记:
<|begin_of_text|>:相当于BOS(序列开始)标记,表示文本的开始。
<|eot_id|>:相当于EOS(序列结束)标记,表示文本的结束。
<|start_header_id|>{role}<|end_header_id|>:用来标识一条消息的角色,角色可以是“system”、“user”或“assistant”。
基础模型调用
调用基础模型进行文本续写比较简单。在起始标记<|begin_of_text|>后面直接拼接用户输入即可,模型会基于此生成后续内容。
<|begin_of_text|>{{ user_message }}对话模型调用
对于单轮对话,格式就需要组织一下了:1) 先用<|begin_of_text|>开头;2) 用角色标签指明这是用户输入;3) 填入具体的用户消息;4) 用<|eot_id|>结束这段输入;5) 再指明下一个角色是助手。模型就会在这个prompt之后生成助手的回复内容。
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
{{user_message }}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>如果想加入系统指令来设定助手的行为,可以在用户消息前插入系统提示,格式如下:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{system_prompt }}
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{{user_message }}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>扩展到多轮对话也是同样的逻辑,只需按顺序交替拼接用户和助手的历史消息即可:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{system_prompt }}
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{{user_message_1 }}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
{{ model_answer_1}}
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{{user_message_2}}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>4.下一步计划
更大的还在后面:Llama3 400B模型正在训练中…