Deepseek 视觉模式终于要来了!
刚刚,DeepSeek的视觉模式来了
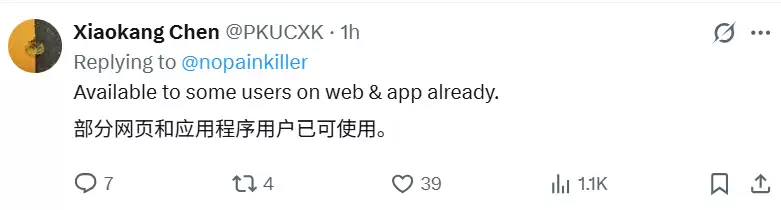
就在不久前,DeepSeek的两位研究员在社交平台X上发布了一条动态,透露了一个重要进展:DeepSeek的视觉模式已经进入灰度测试阶段。这意味着,部分网页端和移动应用的用户已经可以抢先体验这项新功能了。网络上,已经有网友晒出了自己的使用截图。
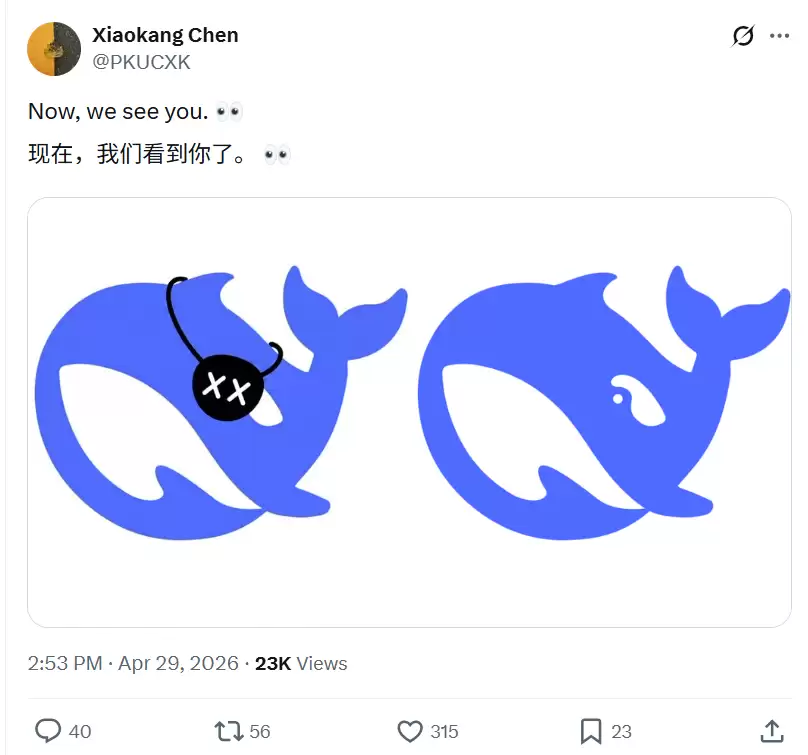
过去,用户们常常带着一丝遗憾地评价:“DeepSeek能力很强,但为什么不能识别图片呢?” 如今,这个被反复提及的“短板”,终于迎来了补强的时刻。所谓的“视觉模式”,正是为了让大模型突破纯文本的局限,升级为能够理解图像输入的多模态智能体。

技术层面的证据更加确凿。通过开发者工具对 chat.deepseek.com 的 settings 接口进行抓取,可以清晰地看到后端配置已经下发。关键参数包括:“model_type”: “vision”、“name”: “识图模式”,以及描述“图片理解功能内测中”。更重要的是,其“enabled”状态为 true。这充分说明,识图功能的后端服务已经就绪,只是目前处于默认关闭、且用户无法手动切换的内测状态。
这个时间点选择得相当微妙。就在上周五,DeepSeek刚刚发布了其V4版本模型,以1.6T的总参数量和在开源模型中的SOTA(当前最优)性能,引发了广泛关注。视觉模式的测试,无疑预示着DeepSeek V4正在补齐其多模态能力的关键一环。这标志着,它正从一个纯粹的文本大模型,正式迈向一个功能更全面的多模态时代。
环顾当下的顶级模型赛场,多模态早已成为入场券。无论是OpenAI的GPT系列、Google的Gemini,还是Anthropic的Claude,都将图像理解、视觉推理乃至多模态智能体能力作为标配。对于志在顶尖的DeepSeek而言,补上这一课,是必然且关键的一步。
现在,“鲸鱼也能看见了”。相信大家和业界观察者一样,都充满了好奇:DeepSeek的“视觉”效果究竟如何?它的图像理解能力能达到什么层次?这无疑是接下来最值得关注的焦点。
已经获得灰度测试资格的朋友,不妨现在就上传几张图片,亲自测测它的实力吧。