FlashQLA - 通义实验室开源的高性能线性注意力算子库
FlashQLA是什么
简单来说,FlashQLA是通义实验室开源的一个高性能线性注意力算子库。它基于TileLang实现,专门为优化Qwen系列模型的Gated Delta Network(GDN)注意力层而生。
这个库的核心价值在于,它通过一系列精巧的底层优化——比如算子融合、Gate驱动的卡内序列并行(AutoCP)以及Warp-Specialized设计——在Hopper架构的GPU上,实现了显著的性能飞跃。具体来看,相较于之前的FLA Triton实现,其前向计算能获得2到3倍的加速,反向计算也有约2倍的提升。这套方案覆盖了从2B到397B的多种模型规格,无论是大规模预训练还是端侧推理,效率都能得到切实提升。
当然,要享受这些优化,环境有明确要求:需要SM90架构(即Hopper)、CUDA 12.8及以上版本,以及PyTorch 2.8+。
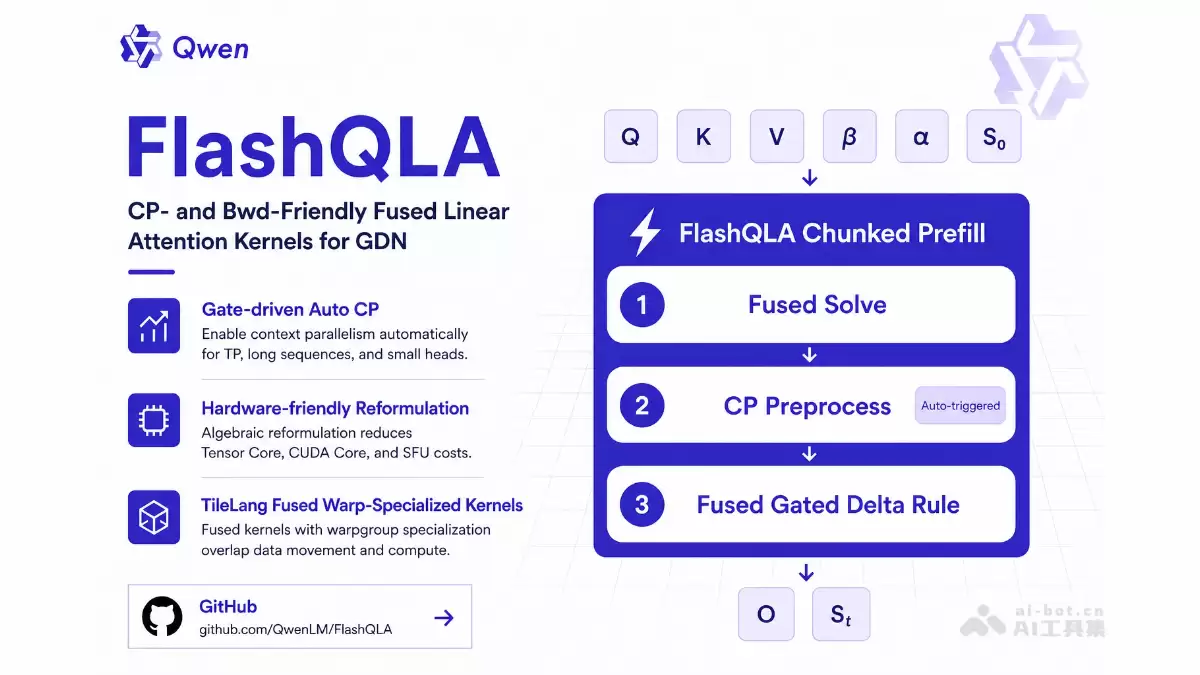
FlashQLA的主要功能
- 高性能线性注意力算子库:它的目标非常聚焦,就是深度优化Qwen全系列模型的Gated Delta Network(GDN)注意力层。
- 算子融合加速:对GDN Chunked Prefill的前向与反向计算流程进行了合理的算子融合与性能优化,减少内核启动和内存访问开销。
- 全规格模型覆盖:支持从轻量级的2B到庞大的397B模型,并且覆盖了TP1到TP8(张量并行)的各种部署场景。
- 双层级API接口:既提供了与FLA签名对齐的high-level API,方便快速上手;也开放了底层的fwd/bwd入口,满足深度定制需求。
- 变长序列支持:内置了varlen变长序列处理能力,能够更好地适配真实训练和推理中不均匀的数据分布,提升实用性。
FlashQLA的技术原理
- TileLang Warp-Specialized Kernel:基于TileLang构建了关键的内核融合(fused kernel)。其精髓在于warpgroup specialization设计,让数据搬运、Tensor Core计算和CUDA Core计算能够高效重叠,充分榨取硬件性能。
- 自动化卡内序列并行(AutoCP):巧妙地利用了GDN gate的指数衰减性质。在TP、长序列、小头数等特定场景下,系统会自动开启卡内序列并行,从而有效提高GPU SM的利用率,解决了传统方案并行度不足的问题。
- 滑动窗口warmup机制:针对具有衰减特性的线性注意力头,仅需6到8个chunk的预热(warmup)就能精确获得子序列的初始状态。这个机制直接跳过了修正量M矩阵的计算,大幅降低了CP预处理的开销。
- 硬件友好的代数改写:对GDN Chunked Prefill的前向和反向流程进行了代数变换与化简。在确保数值精度的前提下,有效降低了Tensor Core、CUDA Core及SFU(特殊函数单元)的硬件开销。
- 兼顾访存与并行的折中架构:没有追求极致的完全融合(fully-fused),而是将计算流程拆分为两个fused kernel,并在中间插入CP预处理。这种设计避免了在小batch或TP场景下,fully-fused kernel因并行度不足导致的GPU利用率低下问题,在访存和并行间取得了更好平衡。
如何使用FlashQLA
- 环境检查:首先确认硬件为NVIDIA SM90(Hopper架构,如H200),并确保软件环境满足CUDA 12.8+和PyTorch 2.8+的要求。
- 安装部署:从GitHub克隆FlashQLA仓库,通过pip完成编译和安装。
- 模块导入:在Python代码中,导入核心函数
chunk_gated_delta_rule。 - 数据准备:准备好输入张量q、k、v以及gate参数g、beta,务必确保各张量的形状符合接口要求。
- 执行计算:调用
chunk_gated_delta_rule函数,传入对应的参数,即可获取输出结果O和最终状态。 - 高级配置:如果需要处理变长序列,可以传入
cu_seqlens参数;若要进行状态续传,则可传入initial_state。 - 自动优化:AutoCP序列并行会根据batch大小和序列长度等条件自动触发,无需手动干预,这一点非常省心。
FlashQLA的关键信息和使用要求
- 发布方:通义实验室 / QwenTeam
- 开源地址:github.com/QwenLM/FlashQLA
- 硬件要求:NVIDIA SM90(Hopper架构,例如H200)
- 软件要求:CUDA 12.8+,PyTorch 2.8+
- 支持模型:Qwen3.5 / Qwen3.6系列(支持的头维度从64到8,对应TP1至TP8配置)
- 加速效果:前向计算2–3倍加速,反向计算2倍加速(对比基准为FLA Triton Kernel)
FlashQLA的核心优势
- 兼顾访存与并行的折中架构:通过将计算拆分为两个fused kernel并在中间插入CP预处理,巧妙地规避了fully-fused kernel在小batch/TP场景下GPU利用率低的问题。同时,这种拆分也减少了HBM反复读写中间变量的访存开销。
- AutoCP自动开启机制:该机制并非始终开启,而是设置了智能触发条件:仅在
batch_size × num_heads ≤ 40或batch_size × num_heads ≤ 56 且 seq_len ≥ 8192时自动激活卡内序列并行。这避免了不必要的冗余计算,自适应地平衡了并行度与访存代价。 - 滑动窗口warmup机制:利用GDN gate的指数衰减性质,对于60–80%的线性注意力头,仅需6–8个chunk的warmup即可精确获得子序列初始状态。此举直接舍弃了修正量M矩阵的计算,大幅降低了CP预处理开销。
- Warp-Specialized计算重叠:基于TileLang的warpgroup specialization设计,在同一个SM内实现了生产者与消费者warpgroup的协同工作。通过ping-pong结构,有效遮盖了数据搬运与Tensor Core/CUDA Core计算之间的延迟。
- 硬件友好的代数改写:通过对前向和反向计算流程进行深入的代数变换与化简,在不影响数值精度的前提下,有效降低了Tensor Core、CUDA Core及SFU的硬件开销,让计算更贴合硬件特性。
FlashQLA的项目地址
- 项目官网:https://qwen.ai/blog?id=flashqla
- GitHub仓库:https://github.com/QwenLM/FlashQLA
FlashQLA的同类竞品对比
| 对比维度 | FlashQLA | FLA (Flash Linear Attention) | FlashInfer |
|---|---|---|---|
| 定位 | Qwen GDN专用高性能算子库 | 通用线性注意力算法库 | 通用LLM推理优化引擎 |
| 技术路线 | TileLang Warp-Specialized Kernel | Triton Kernel分步实现 | CUDA Kernel预编译优化 |
| 前向加速 | 基准 | 2.95× slower | 5.33× slower (397B TP8 32K) |
| 反向加速 | 基准 | 2× slower | 不支持 / 未优化 |
| 序列并行 | 自动卡内CP (AutoCP) | 手动配置CP | 不支持GDN专用CP |
| 算子融合度 | 双fused kernel + CP预处理 | 每步独立kernel | 通用fused attention |
| 滑动窗口优化 | Gate warmup机制,免M矩阵 | 标准CP需计算M矩阵 | 无 |
| GPU利用率 | 自动提升小batch/TP场景SM利用率 | 小头数场景利用率受限 | 通用场景优化 |
| 硬件要求 | SM90 (Hopper), CUDA 12.8+ | 通用NVIDIA GPU | 通用NVIDIA GPU |
| 模型适配 | Qwen3.5 / Qwen3.6全系列 | 通用线性注意力模型 | 通用LLM推理 |
| 开源状态 | 开源 (GitHub) | 开源 | 开源 |
FlashQLA的应用场景
- 超大模型预训练:覆盖397B、122B、35B、27B等全系列Qwen模型,支持长达256K的上下文训练。能显著降低注意力层在端到端训练中的算力与时间开销,加速模型迭代。
- 端侧agentic推理:针对batch_size=1、小尺寸模型(如2B/0.8B)的chunked prefill场景,通过AutoCP机制提升小头数下的GPU利用率,从而加速端侧智能体的实时响应速度。
- 大模型线上部署:在TP(张量并行)场景下处理coding agent等长序列输入时,能有效解决chunked prefill因开不出足够大batch而导致的GPU利用率瓶颈问题,提升服务吞吐量。
- 通用GDN/线性注意力架构加速:适用于任何基于Gated Delta Network或线性注意力架构的大语言模型训练与推理,提供了一套开箱即用的高性能算子替换方案。